
This blog takes a look at a couple of ways to design Internet connectivity in the presence of Layer 3 data center interconnect (DCI). There’s an inherent design question in this situation: Are two data centers connected via Layer 2 DCI one site or two sites?
After discussing that, we’ll then segue into a Lesson Learned about Failover Testing.
This is based on a real-world situation. My purpose in running through this is because there is something to be learned from this. I’ve kept things anonymous since I have no wish to embarrass or criticize anyone, especially not in public.
Internet Connectivity
“Organization X” was configured with routing over DWDM-based Metro Ethernet services between two data centers / user locations, A and B. Most users worked at site B. OTV transported some VLANs between the two data centers on top of the routed interconnects.
The organization also used dot1q tags and VRFs to securely interconnect the border complexes at the two sites. That is, the Internet router and border switch at each site each had a path to different VRFs on the Layer 3 data center interconnect devices. Those VRFs routed to the other data center with segmentation via different dot1q tags than the global routing was using.
The following diagram shows the basic setup.
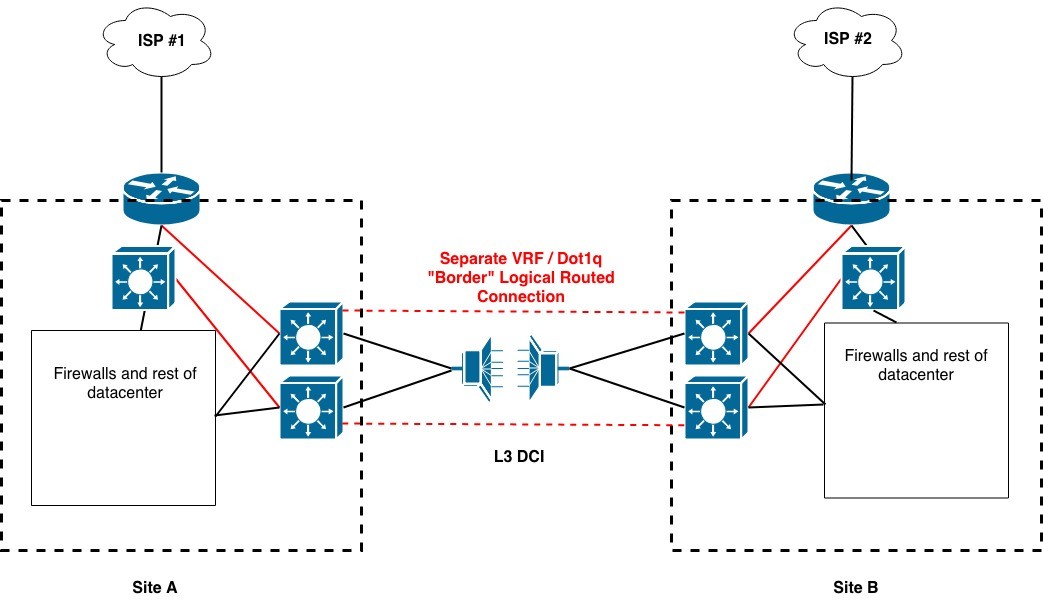
Should one provider or Internet router fail, the cross-connect would allow traffic to reach the Internet via the other site.
Note: One of the red links connects to the border switch inside the border router, protecting against router as single device failure – but likely not loss of power or other event impacting both devices.
Can you think of a better way to do this? When there’s one Internet or WAN connection per site, it can only connect to one router or switch. Would dual border switches be better?
Organization X had one Internet connection at each site. The connections used two different providers. They were set up to prefer one connection, the one at site A. That is, default was weighted internally to prefer egress via site A, and the public prefixes were prepended out of site B so that return traffic would prefer site A and preserve symmetry.
To their credit, organization X had done HA pair failover testing.
To their dismay, the datacenter interconnect failed, due to a power single point of failure that had not been noticed. This led to site B’s traffic exiting to the Internet from site B, but return traffic entering site A and not being able to reach site B. Since the border interconnects went through the data center interconnect as well, the symmetry of Internet flows could not be preserved.
Diagnosis and Solutions
The fairly obvious problem was that the public prefix advertisement and prioritization of site A was not sensitive to loss of connectivity to site B.
One solution would be to use different public /24s or provider-supplied public addressing at the two sites. In case of outage, outbound traffic could egress and NAT to the other site. The main drawback would be that failover would drop TCP sessions.
A refinement would be to have two public /24 blocks, have site NAT or DMZ hosts each use a site-specific block. Then advertise the blocks between the Internet routers and do AS path prepending so that inbound traffic would prefer “the main site” for each block. In case of Internet outage at one site, traffic could still enter and exit via the other. In case of DCI failure, each site could operate standalone.
A third choice was to set up a VPN tunnel between the two Internet routers and use that as a backup path should DCI break. That has the virtue of simplicity, and the drawback of performance impact from doing VPN.
Gaining Perspective
Stepping back from all that, what really struck me about this situation is that when you’re doing DCI (L3 or L2), you sort of have one site and yet again the reality is there are really two sites. With L2 DCI, you’re more on the one site side of things. In particular you have one site from a failure domain perspective.
So, what’s the best way to think of this situation from a design perspective? I’m ok with treating it as one site if the DCI is diverse. In this case, it was not fully diverse.
Consider what you’d do if instead of DCI, you had a longer distance WAN / MetroEthernet link between the two data centers and sites. How would your design change? Which of the approaches above would you use or would you do something different? Does that impact what you’d do for this design situation, with relatively short-range DCI?
Conclusion: If you have two sites that are expected to act more like one large site, take steps to prevent partitioning into two separate sites. If you can’t eliminate that risk, then treat them as two separate sites.
Dual-ing Devices?
Another design question lurks here. Most of the network devices at each site were in pairs, except for the Internet links and single ISP per site. Organization X was reportedly fairly comfortable with failing applications over.
So, is having dual devices necessary? Or a waste of money?
My experience has been that application failover is very nice to have, but all too often has post-event “cleanup” consequences. Database re-synch, shifting the master server, whatever. Thus, it may be a good idea to have network redundancy to minimize the number of times we stress-test application failover — which normally does not get tested as often or under random circumstances as we do with network equipment.
How do you feel about this? If you can readily fail over to the other data center, do you need two network devices at each position in each datacenter?
Perhaps 99.999% of the dual-datacenter DCI designs I’ve seen use double devices everywhere they can. Is that due to a design habit (or selling more hardware), or is it needed?
Any physical data centers with North / South halves have usually had one device per half and really have to be considered a single site with partial internal redundancy. In the old days of spanning tree everywhere (and we’re still not fully out of those days), those halves were still definitely a single failure domain.
The “cloud native” thought of the day here is that if the applications or app components are built to be resilient upon failure, then the network might not have to be as robust. But until that day arrives across all your apps …
Applications based on clustering with “quorum” or “witness” are yet another factor. One would hope that how they react to various types of network failure has been considered and perhaps expectations were documented. I say “hope” since I’m pretty sure discussion and documentation are both rare for such applications. Reading suggests that distributed databases are very easy to do wrong.
Failover Testing
There may be a human tendency when doing failover testing to fail one device and test failover to the other of a HA (high availability) pair. And maybe vice versa.
But other failure modes can occur. Does the failover still work if a link fails instead of one of a router pair failing?
Conclusion: Build a list of things that can fail. This can be helpful for making sure your HA plans don’t overlook some possibilities. It also can be the basis for documented testing of failover on a periodic basis.
One lesson I’ve learned by watching organizations have outages is that Murphy’s Law of Outages applies. If there is something you haven’t (recently) tested, or have taken for granted, that’s what will fail.
My favorite case of this is from the ISDN era (yes, I’m that old). A site had a failover failure. It turned out the local telco had gone to 10-digit dialing, and nobody had remembered to update the ISDN phone numbers in the router configurations. Oops! Testing would have caught that one.
I’ll repeat something here that I’ve seen some large firms (especially stock market / financials) do recently: they plan and test every possible pair failover / failback scenario annually. That is done for each router, switch, or dual link situation. The review catches things like misconfigured HSRP or HSRP VIP next hops. Unfortunately, such testing is usually limited to HA device pairs, because testing other types of failure would require too much staff time and tie up too many outage windows.
Comments
Comments are welcome, both in agreement or constructive disagreement about the above. I enjoy hearing from readers and carrying on deeper discussion via comments. Thanks in advance!
—————-
Hashtags: #CiscoChampion #TechFieldDay #TheNetCraftsmenWay #DataCenter #Failover #Routing #Switching
Twitter: @pjwelcher


NetCraftsmen Services
Did you know that NetCraftsmen does network /datacenter / security / collaboration design / design review? Or that we have deep UC&C experts on staff, including @ucguerilla? For more information, contact us at [email protected].