
Life used to be simple. Or so we fondly think (details and pain tend to vanish in the rear-view mirror).
This blog looks at some of the design aspects around providing Security, and how this has been changing: the evolving landscape of network security.
My hope in doing this is that having some perspective may help you look at what your organization is doing, and some of the options for simplification or what is usually its opposite, tighter security.
Apologies in advance: this blog became a bit long! It also repeats some themes from prior blogs. I plead necessity: presenting this as a self-contained topic!
The summary version of this blog might be something like: “agent based ZT/ZTNA is going to kick ass, but hardware-based firewalls will remain useful.”
Partial History of Network Security
Security used to amount to putting a firewall between your network and the Internet. Two firewalls and Internet links for redundancy. Duplicate at a second site if needed (financial org, etc.). Deal with all the implications for routing and automatic failover. Done! (Ok, a bit of oversimplification here, but not that much!)
Logically, what’s going on there is inserting the desired security services somewhere between any two end systems, i.e., in the path of every flow of concern. That approach started with the flows to the “evil” Internet and got more complex, as we’ll discuss next.
I will refer to the location(s) where the security services are running as the Policy Enforcement Point (PEP). That acronym may be a bit dated (or not), but it describes the functionality well. There may be many such PEPs, and they may not all be doing the same task. I.e. some might be enforcing access lists and traffic policy rules, others might be inspecting traffic, or logging flows, etc.
Somewhere along there, required Security became about more than the Internet anymore. Among other things, most sites wish to detect and/or prevent lateral spread, where a system is compromised, and then other systems attacked from within, i.e., firewalls, being the hard shell around the soft interior, no longer sufficed.
Some of my prior blogs talked about this. See the Links section below. (I’m amazed at how many blogs I seem to have posted to https://netcraftsmen.com that contain the word “firewall” – per Google search.)
The broad topic in those prior blogs was other places you might want a firewall and thinking through which flows the different firewall (PEP) locations might provide enforcement for.
Here’s the diagram I built for discussing this, in the hope it may be useful. You may well have seen this one before!
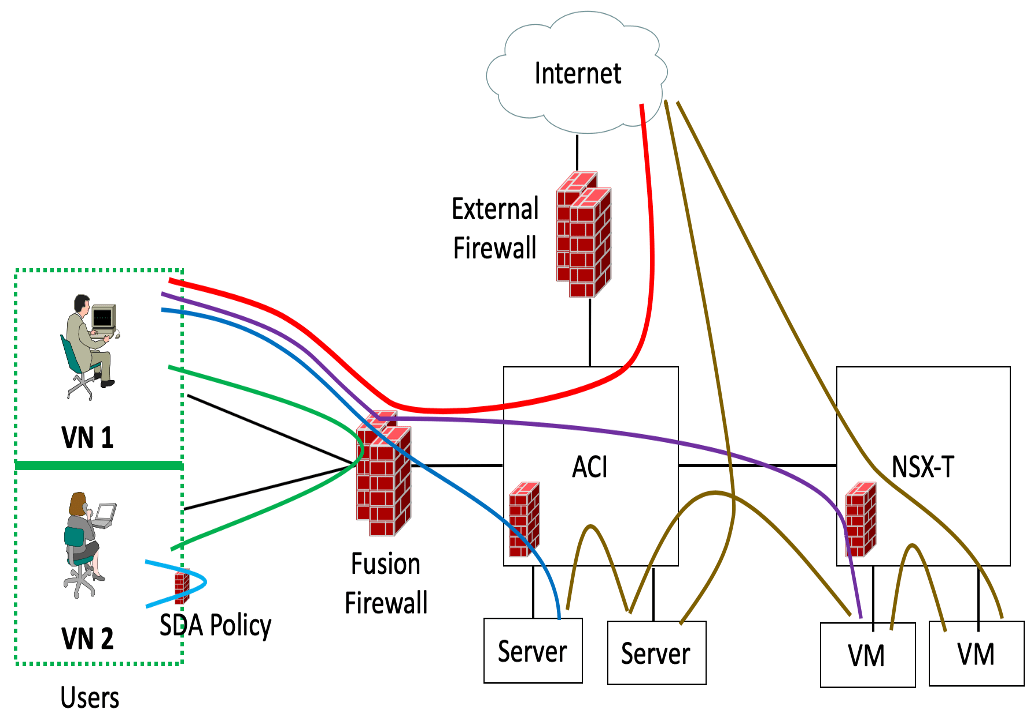
The limitation implicit in the above diagram is that it secures major network components from each other. The left side of it addresses campus lateral spread perhaps: see the discussion below. Lateral spread in the data center is somewhat similar but may require different products/tools.
As our networks evolved, along came segmentation, both macro and micro. My definitions:
- Macro-segmentation: VRFs or VNs: separate routing domains
- Micro-segmentation: virtual segmentation, locally enforced either by switches or end system agents
Both those forms of segmentation gave us new options but increased complexity.
Macro-segmentation was about compartmentalizing the network and forcing traffic between the macro segments to transit a firewall. It came with “plumbing” aspects: creating VRFs and/or VLANs to separate the traffic segments until they reach the firewalls. The trade-off there (channeling Russ White) was to put up with the “plumbing” configuration (not too painful) because firewalls were (are?) expensive, and having them all over the network would be complex to manage.
In other words, we have a few firewalls. How to we broaden their use to support filtering flows between macro segments?
Also note that macro-segmentation prevents lateral spread of malware between VRFs or compartments, but not within them.
“Network-based micro-segmentation” (at least for Cisco) requires enforcement by switches, which is not stateful. It allows using Security Group Tags (SGTs) assigned based on login, device type, and other characteristics (cf. ISE) to identify micro-segment membership. This is particularly useful for “softer” boundaries, e.g., different types of users or campus devices.
One limitation is the use of SGTs allows a user or device to belong to only one security group. If you need fine distinctions, you have what I call the Venn Diagram problem: someone being in A and B but not C nor D. With four groups like that, 2^4=16 different combinations… doesn’t scale well. (The visual for this is “the matrix” in DNAC, showing source/destination groups: each box in that n x n grid requires a security policy.)
For more on that topic, see also the recent SGT blog at: https://netcraftsmen.com/designing-for-cisco-security-group-tags/
So, all that was workable (for some value of workable), provided you wanted flow/traffic-based enforcement.
More Security Functionality
However, growing threats led to further security requirements. Traffic inspection, malware detection, etc. Those are things that high-speed switches and routers cannot do, at least not currently. The reason is chips cannot do them; they need more complex programs and thus must be done in software. (Possible exception: Aruba switches with Pensando per-interface DSPs?)
That’s an old story, going back to when people complained that their CheckPoint or other firewall had all sorts of great functionality but died under the load if you turned on all the capabilities. I still see occasional complaints (pick your vendor) that firewall marketing did not sufficiently cover capacity and sizing.
Definitions
Recent cloud-based security technologies such as SASE and SSE (see below) complicate the picture. (Lately, SASE = SD-WAN plus SSE, more or less.)
SASE (per various sources):
- SD-WAN
- Secure Web Gateway (SWG)
- Firewall as a Service (FWaaS)
- CASB (Cloud Access Security Broker)
- ZTNA (Zero Trust Network Access)
- Centralized management
SSE (per zScaler and Gartner):
- Cloud-based security services, including at least SWG, CASB, ZTNA
- May include FWaaS, Remote Browser Isolation (RBI), Data Loss Prevention (DLP), etc.
For this blog’s purposes, I will interpret “cloud-based” as control being in the cloud. Some of the PEP functions might be local, in my definition.
And in real life, all but the smaller or lower-tech sites seem to be deploying a mix of solutions.
Analyzing Your Requirements
So, what goes into the Security Requirements mix?
The following lists significant places in the network:
- Site networks
- Campus networks
- Data center networks
- Internal cloud services (“the stuff that used to be in the data center”)
- External services, SaaS, business partners (i.e. servers, services)
- External workers
- Internet
- Edge networks
- Isolation and/or IOT/OT networks (etc.)
- Anything else?
Traditional site designs hang various campus (office) and data center switching layers off separate core devices that connect to an overall site core. Sometimes those roles were shared.
The site core devices then connected to WAN routers, and possibly firewalls (FWs) and Internet routers. Call that the “external-facing module(s)”.
As cloud came along, any dedicated connections to CSPs or CDNs probably also attached there, sometimes leveraging VRFs in the firewalls, and sometimes using separate FWs to guarantee better isolation and separate fault domains. Adding dedicated firewalls for each such function can lead to “site edge firewall farms.” Doing this at three data centers during migration (old, new, colo) with optimal failover can lead to interesting routing challenges, especially if (a) you don’t have a coherent plan and (b) if you don’t run BGP to rather than through the firewalls.
Edge networks were likely kept separate, and perhaps trusted.
IOT/OT might have been on a separate network.
However, that is changing. As building controls permeate building infrastructures, and similarly as networked medical devices penetrate hospitals, IOT/OT devices need to be dealt with. Admittedly, building controls tend to arrive with new or remodeled buildings, i.e. slowly.
Medical settings can be more of some team adding stuff and expecting the network to support it, with or without prior discussion with the network team. Security might be an after-thought.
I suspect many of us have had to deal with discovering new stuff on the network, often when it is having problems due to ill-conceived multicast or something, and then (a) having to make it work, and (b) secure it.
Anyway, some of us started securing all this by adding more and more FWs as PEPs between or within the components listed above. Within a site or building, VLANs and VRFs might have sufficed. Across leased fiber or SD-WAN, maybe easy, maybe not.
That’s basically why macro- and micro-segmentation became needed. On the macro-segmentation front, VRFs (and, to a less scalable extent, VLANs) provided a way to logically isolate traffic by function and security level. This permitted using FWs to control traffic between the macro segments. There would be little “hair-pinning” (out to FW, back to same switch) in most networks: isolated segments would be much more likely to have traffic to the data centers. And latency is not usually a big concern if VRF egress is in the same site or building.
One remaining area for improvement is that macro-segmentation does not directly address monitoring same-VRF traffic.
Micro-segmentation is less strict, leveraging the local switches to enforce non-stateful access lists. It allows same-segment enforcement, depending on the implementation.
Extending all this between sites however became messy. For VRFs, you had to do “plumbing” to extend the VRF to a firewall, to a router, and over your SD-WAN or other network to other sites. One side effect was that we (or the SD-WAN implementation) often ended up doing point-to-point VPN tunnels, per VRF, for WAN connectivity. (Scaling/performance caution!)
Internet and Cloud were less of a problem, so we typically still run such traffic through a firewall. Coordinating FW rule changes with Cloud developers could be fun.
Side rant: Have you ever seen *documentation* of a FW ruleset? As in who created the rule, when, why, what it is supposed to be doing (versus what was configured)? Let alone annual audits to review rules for correctness and completeness and remove rules that are no longer needed? Yeah, nobody wants to hurt their brain reviewing 100s to 1,000s of un-documented and un-commented FW rules.
One nice aspect to having physical PEPs in paths is that one could readily observe traffic flows for lapses in enforcement, at least for traffic through those PEPs. With micro-segmentation and switch-based enforcement, one may have to work a little harder (and capture a lot more flow data) to detect lapses, and policy errors.
Refocusing the Discussion: Key Considerations
It all comes back to requirements.
So, what are you trying to do, and what do you need to do, regarding what forms of enforcement, and where?
As we transition to Zero Trust (ZT), we are likely moving from putting PEPs in between the above sorts of components, to doing more with authentication-based access controls.
Do the authentication-based controls replace the prior FW, etc. rules? Or supplement them? Or do things flip, where the authentication is primary, and the FW “belt and suspenders”? Both?
Why Might I Want Cloud-Based Management?
Cloud-based provides centralized management = simplicity. Pay for someone else to deal with keeping the controller running and secure.
If your requirements require internal controllers so that loss of cloud/Internet does not cause problems, that limits your vendor choices somewhat. If the controller is e.g. a Kubernetes cluster, managing it can add complexity. Ditto managing a pile of security certificates.
Another choice might be to NOT have a central controller. But configuring security policy, not just access lists but web gateway and trust enforcement, across distributed firewalls or other devices is complex.
Cisco has been refactoring their products since its “some local, some cloud” approach had some technical rationale in favor but was complex to understand and administer. Note also their Meraki line: maybe fewer options, bells, and whistles, but simpler.
Why Do I Care About the PEP?
Let’s shift focus to thinking about new Security products you might add to the network. This assumes the Security team isn’t going to haul off, buy something, and then tell you how to stick it into the network.
As part of the Security product evaluation, there are a couple of things it might be useful to think about. Things that may have gotten skimped on in the past. Like: what are the real requirements?
Product evaluation/design planning considerations:
- Where is the PEP role? How many <things> will we be adding to the network, and where? How much work will that entail? How much recurring work?
- How are they managed? Is the controller of PEP communications secure and manageable? (Thinking about Cisco Viptela: very secure control communications but surprise with an expired certificate.)
- Is enforcement concentrated or distributed? In either case, is there a potential throughput or latency concern as traffic increases? Processor capacity is one factor in this. Re-routing traffic and latency another possible factor.
- Red flag: processor-based stateful ACL enforcement. Worse: inspection.
- Red flag: encryption overhead can bog down processors in shared devices, be they firewalls, routers, or switches. (See also my separate blog re Cisco ASAc.)
- What trade-offs does the product entail?
Analogy: line waiting to go through TSA at the airport. Security analysis: definitely a potential bottleneck. They’ve improved throughput by caching, i.e., TSA Pre-Check, and parallelism, but often are limited by chip-side space available, etc. Exercise for the reader: think about other ways they might have done this. Is TSA Pre-Check analogous to ZTNA?
Concerning CPU burden: Elisity’s product apparently offloads ACL enforcement to the Cisco Catalyst hardware. Hence efficient but stateless.
SASE and SSE products may take more direct paths to the cloud for lower latency, typically using regional distributed vendor POPs. That may approximately match your WAN or VPN latency due to fiber paths (assuming vendor POPs are located at/near Equinix or other long-haul fiber meeting points).
Compare that to requiring remote site traffic detouring across the WAN to get to the corporate egress firewall.
If the SASE or SSE product functions by tunneling traffic to a POP where a virtual firewall or other software provides the security functionality, you may have added latency due to the detour plus the PEP processing. That’s a factor with zScaler, for instance, where user traffic out of a device or a site is tunneled to their local POP. They’ve got a lot of distributed POPs. Pre-purchase checking might include seeing if your organization’s locations are all sufficiently “close” to their POPs. Cisco is apparently building out a similar POP network for its managed SSE service. That’s probably a moving target if you’re concerned about the international site’s proximity to PEPs.
The difference may be small if your organization is local to some region. Or not.
Revisiting Macro and Micro-Segmentation
Are VRFs going away: require plumbing? Note that ZTNA can provide more granular enforcement simplicity.
But VRFs provide firmer security boundaries, guaranteeing that a security rule error or other lapse won’t leak. Yet both approaches come down to policy rules, either in the ZTNA, etc. products or in the firewall.
My guess is that ZTNA and simplicity are going to be popular with small to medium size businesses for ease of use. For medium to large-size businesses, evolution may be slower, with the primary focus shifting to ZTNA or ZT, retaining firewalls for extra protection, at least in certain enforcement locations.
Links
- https://netcraftsmen.com/designing-for-cisco-security-group-tags/
- https://netcraftsmen.com/designing-security-who-does-what-where/
- https://netcraftsmen.com/where-to-stick-the-firewall-part-1/
- https://netcraftsmen.com/where-to-stick-the-firewall-part-2/
- https://netcraftsmen.com/securing-sd-access-traffic/
Conclusion
I hope the above discussion will be useful in your Security planning and product evaluation going forward.
I cannot help but see the potential performance advantage to distributing enforcement across endpoints. The obvious drawback there might be some malware defeating the enforcement somehow?
My crystal ball predicts a shift to agent-based, with some phase-out and some retention of firewalls etc. in traditional locations.
What do you foresee in this space?
Let’s start a conversation! Contact us to see how NetCraftsmen experts can help with your complex challenges.


