
I’m getting the impression some people think Cisco Nexus 9K automatically means doing ACI. Not so!
There are several valid ways to design around an N9K. The ones that come quickly to mind are:
- Two big Nexus 9Ks running under NXOS for two-switch datacenters (small to medium-sized organization, low complexity)
- Some mix of core/access or spine/leaf N9K switches in NXOS mode, just doing VPC to a small number of pairs of leaf N9K switches (medium-sized, low complexity)
- Spine/leaf topology, NXOS, L3 fabric with VXLAN in some form, preferably VXLAN + EVPN (medium-sized, moderate complexity). VRFs are available as well, for a multi-tenancy design or approach.
- Spine/leaf N9Ks, ACI (medium- to large- to huge-sized, moderate complexity, learning curve, SDN/higher degree of automation)
Let’s take a closer look at these.
If your organization is heavily virtualized, you can fit an awful lot of VMs into a blade chassis. A rack might easily hold four Cisco UCS blade chassis, with eight server blades each, running, say, 30 VMs on each blade server, for a total of 960 VMs. Each blade chassis might need 2 x 4 x 10 G uplinks, so that rack would need, say, 32 x 10 G uplinks. That’s not a lot of upstream switch space! Several racks worth of such might use a couple of line cards worth of 10 G ports on the switch they attach to.
Hence: the two-switch datacenter.
I have been noticing the VM density possible for years. Credit goes to Ivan Pepelnjak for the two switch aspect; see his article here.
If you’re a fan of a modular approach, at some point you might prefer a spine-leaf approach to just having two fairly big switches at the core of your datacenter. That’s where the second option comes in. It might use Top of Rack (ToR) switches for each rack or short row of racks, and aggregate them back on core or spine switches. If you do “wide” VPC to each leaf or access switch pair, you’ll have a relatively Spanning-Tree Protocol (STP) free datacenter. The main drawback I can see is that you’ll likely have VLANs spanning that fabric, which exposes your datacenter to some risk of STP issues.
To handle that, and provide for bigger scale with robustness, you can instead build an L3 fabric (option No. 3 above). You can then run VXLAN overlays on top of the fabric for robust larger scale virtual L2 anywhere in the datacenter. If you add BGP and the Cisco EVPN functionality, BGP will track {MAC address, IP address} locations for you, every leaf switch will act as a default gateway, and you’ll have a robust but flexible datacenter fabric.
NetCraftsmen is building that out now for one customer. We view it as a modern version of FabricPath, which is working well for us at another customer site. While VXLAN/EVPN currently lacks some of the amenities of OTV for Datacenter Interconnect, it has potential in that arena as well. It is also multi-vendor and standards-based, subject to the usual caveats of vendor interoperability and feature support. The potential for /32 host-specific routing rather than LISP is also intriguing (up to a moderate scale, anyway), pending seeing how that evolves. Doing that on an MPLS WAN might well require a WAN overlay such as EIGRP OTP, as most MPLS providers limit the number of routes a customer can have.
We have discovered the need to do some fancy footwork around IP multicast with RP’s outside the VXLAN fabric. I’ll spare you the details.
For further details about VXLAN, see the References listed below.
For those who haven’t been tracking ACI and spine-leaf, here’s a diagram. The spine switches are at the top, and there could be more than two if greater inter-leaf capacity is desired. Each leaf switch would have the same number of connections to each spine switch. The leaf switches are at the bottom, and might well be connected in pairs to support edge VPC port-channels. This topology is an example of a CLOS tree, providing maximum non-blocking bandwidth between leaf switches.
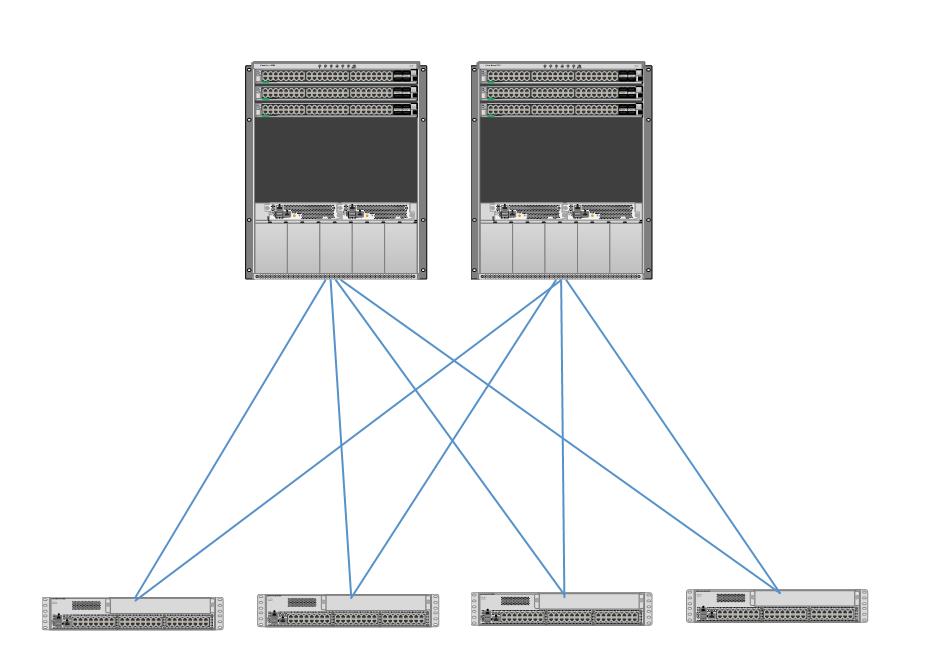
The last option is to instead build out the spine leaf fabric with N9Ks configured by ACI, running the ACI OS. For SDN and automation of policy in large datacenters, nothing beats ACI. Having said that, some organizations feel they’re not ready for ACI, not ready for the policy aspects of ACI, need to adhere to open standards, or want to avoid Cisco lock-in. If your Security team doesn’t play well with others or is anti-Cisco, that might also be somewhat of a counter-indication for ACI.
If you’re interested in VXLAN but want automation, there are a couple of solutions. Cisco Prime DCNM 7.1 and later has VXLAN supporting functionality, including apparently some support for VXLAN to non-N9K switches. Version 7.2(3) apparently includes EVPN support. See “Cisco Programmable Fabric” for details.
There is also Cisco’s Nexus Fabric Manager, licensed on a per-N9K basis. For TAC support, you must be running it on the supported appliance, rather than as an OVA on a hypervisor platform. A download is apparently available for lab testing. I found myself getting hung up on the brownfield/greenfield aspect (i.e. does the product insist on total control) when I realized that if you’re configuring a VXLAN fabric, you may not need to go outside what the Fabric Manager does. A brief session at CiscoLive suggested that Nexus Fabric Manager might well simplify your buildout and operational management of a VXLAN + EVPN fabric. No, I have not had the chance to get hands-on with it yet.
If you are finding this a bit overwhelming, help is available. As already noted, NetCraftsmen has experience building out VXLAN + EVPN. Just reach out and let’s start a conversation.
On the ACI front, NetCraftsmen has various forms of consulting/training offerings. These entail working with you to set up your ACI fabric, talking through the policy aspects, then configuring a sample scenario as well as Layer 2 and Layer 3 external connectivity to your current datacenter gear. VMware integration and shifting a VM’s connections to ACI is also a good topic. Another possibility is working through the operational aspects of ACI: backing up your configuration, restoring the fabric after an outage, integrating it with your management systems, defining the steps for configuring and testing a bare metal server connection, ditto for a VM, etc. The point is to proceduralize the operations tasks so that anyone can execute them, with consistent quality and no missed steps or accidents.
Testing various forms of failover and practicing troubleshooting might also be useful before putting ACI into production. It would not only build confidence in ACI, but in your own skills at understanding what is going on.
References
Comments
Comments are welcome, both in agreement or constructive disagreement about the above. I enjoy hearing from readers and carrying on deeper discussion via comments. Thanks in advance!

