
 I’ve been doing a good bit of design for organizations that are moving towards dual datacenters. When you double up on datacenters, there’s the associated question of how you interconnect them, Datacenter Interconnect or #DCI.
I’ve been doing a good bit of design for organizations that are moving towards dual datacenters. When you double up on datacenters, there’s the associated question of how you interconnect them, Datacenter Interconnect or #DCI.
I feel like there are a couple of blogs worth of things that need to be said on this topic.
This blog is intended as a relatively brief summary of some recent discussions I had. My hope is to put into perspective the various ways to design for two datacenters — the overall framework of choices. Subsequent blogs may then explore some of the choices and their issues in more detail.
There are three objectives for this blog:
- What requirements might drive a choice of which technologies?
- What is the spectrum of choices and their implications?
- A warning that active-active datacenters do have costs, which might well include complexity.
So without further ado, here are the major choices for two datacenters:
- Layer 3 WAN/MAN between them
- Layer 3 WAN/MAN interconnect, Server Load Balancers (GSLB/SLB) or Akamai for High Availability (HA)
- Layer 3 interconnect, VMware Site Recover Manager (SRM), hot/cold datacenter
- Ditto, but segmented with some VLANs and VMs hot in one site, some in the other
- Layer 2 interconnect, lots of bandwidth, live with any “hair pinning” or “tromboning” of traffic
- Layer 2 interconnect, OTV-like FHRP filtering, perhaps LISP
- Ditto, but add stateful devices (firewalls, SLBs front-ending VMs)
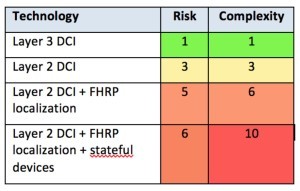
There’s a reason for the above ordering. It represents my current thinking about complexity. As you go down the above list, complexity and risk increase, sometimes dramatically.
The first choice on the above list is nothing special. There’s probably not much High Availability there. Maybe it is a hot/cold DR pair, with replication between the sites. If the main site fails, DR takes place, and after some period of time, the second site will be up and running. Many organizations these days want to do somewhat better than that.
Concerning risk, Layer 2 DCI creates the potential for shared fate, or a shared failure domain. A Spanning Tree event could knock out both datacenters. Even with OTV this can happen, even though OTV does ARP caching and unknown unicast reduction. As learned painfully by at least two sites I’m aware of, you do want to supplement OTV with traffic storm controls and Control Plane policing. Spanning Tree termination means BPDU frames are not passed over OTV. It does not mean a STP loop flood will not pass over the OTV link.
For the record, I’ll agree with Ivan Pepelnjak that if you do need to have Layer 2 Interconnect, OTV looks like the best alternative.
A less risky and mature alternative is to use Server Load Balancers, GSLB, and SLB. Using them plus Layer 3 DCI keeps the datacenters mostly at arm’s length, so they are mostly separate failure domains. If you mess up the GSLB/SLB, yes, they might both be inaccessible to users.
Ironically enough, I see VMware SRM as a tried and true technology, in the sense that it is the old hot/cold datacenter trick but implemented with automation and Virtual Machines. What is nice is that it includes explicit configuration of your RPO objectives, driving the synchronization between datacenters. It does require a cold restart of VMs in the cold datacenter. The old “presto, the subnet is now in the other datacenter” trick applies. Routing directs packets to the right location. The cutover is fairly easily scripted. As noted above, with some discipline, you might even do it with some VLANs and VMs hot in one datacenter, some in the other.
If you’re like a recent customer, planning on operating six months from one datacenter, then six months from the other, a mix of GSLB/SLB and SRM might well fit!
The driver for Layer 2 seems to be mostly vMotion these days, since Microsoft clusters can operate over Layer 3 separation. I totally get how convenient vMotion is for admins. If you have enough bandwidth, a certain amount of vMotion lets you operate flexibly from two datacenters. EMC VPLEX Metro facilitates vMotion without also moving the VM datastore. I just read that vSphere 6 supports long distance vMotion with VPLEX Geo – although vMotion in general requires some Layer 2 interconnect as far as I know.
Where Layer 2 interconnect starts getting more complex is if you want to be “smart.” The problem is that traditional IP addresses and subnets indicate location. But with Layer 2 DCI and OTV, the “stretched VLANs” mean that a stretched subnet is present in both datacenters. That creates the urge to optimize outbound and inbound traffic flows somehow, so they go to the right datacenter.
I personally end up wanting to throw DCI bandwidth at the problem, if the datacenters are close enough. If latency is significant, that becomes less attractive.
OTV-like FHRP filtering “solves” outbound traffic optimization. And Cisco LISP can be used to optimize inbound traffic, at least for your WAN. The Internet might take a bit more work.
Where Layer 2 DCI gets messy fast, however, is if you combine vMotion with stateful devices — typically firewalls and SLBs — and FHRP localization. The issue there is that vMotion will cause asymmetric flows for existing sessions, resulting in eventual dropped user connections, unless you design around the problem. For a while I was blaming this on LISP, but it really is more due to FHRP localization.
I’ve seen some suggestions for how to resolve this. I won’t call them solutions, because they all strike me as ugly and complex. And “interesting,” for various values of “interesting.”
But this blog is long enough already… more in a later blog!
Prior Blogs about Datacenter Interconnect
Ivan Pepelnjak and I have been writing about DCI for a while, as has Cisco. Rather than listing individual blogs in a very long list:
- Google search “datacenter interconnect” on ipspace.net
- Google search “datacenter interconnect” on netcraftsmen.com
- Google search “datacenter interconnect” on cisco.com
Comments
Comments are welcome, both in agreement or informative disagreement with the above, and especially good questions to ask the NFD9 vendors! Thanks in advance!
Hashtags: #DCI, #OTV, #LISP, #CiscoChampions
Twitter: @pjwelcher

