
This is the third blog in an Internet Edge series.
Links to prior blogs in the series:
- Internet Edge: Simple Sites
- Internet Edge: Fitting in SD-WAN
This blog and the next one cover some of the more interesting but undesirable things I’ve seen people do in the Internet Edge. My hope is that some strong opinions and some “real-world stories” may be of interest and helpful from a design perspective!
I’m not 100% sure that this topic is a good idea so early in this Internet Edge series. But then again, this particular blog article IS all about bad ideas and best practices. So here we go.
Bad Practice: RIP Routing
Friends don’t let friends deploy RIP or RIPv2 in the Internet Edge or elsewhere. (I never tire of this item. It’s great for starting debates!) Really, using OSPF or EIGRP is almost as simple as configuring RIP, and they behave better.
Bad Practice: Messy Module Boundaries
It is generally very helpful to have a clean separation between campus, WAN, and datacenter and keep the Internet Edge mostly separate from the rest of the data center. Modular design!
Each of those places in the network works best as a separate module, especially if the component devices are from different vendors, and recently, based on different management, automation, etc., tools.
The whole point of having such modules is to minimize inter-dependencies between modules and tools. With routing as a controlled handoff between modules.
Building with modules also reduces how much any one person has to fit into their head to maintain a given module.
As an example of what not to do, I’ve seen a site, a fairly big company, where HQ had a couple of multi-story buildings with approximately 16 closet switches total. Everything else fed back into the LARGE data center core switches, which also had a lot of data center switches aggregating back to them, plus all the DMZ and edge functionality tied to them. Doing maintenance on those two core switches meant everything would be potentially affected, other than other sites.
So that was a clear lack of modules, boundaries. I’m OK with a data center core pair; what I would have liked to have seen in that case was a pair of separate building core switches and something similar for the Internet / WAN edge (given that there were a lot of DMZs and other things in it). There sort of were DMZ cores, but they were so tightly tied to the data center cores by a lot of VLANs and cabling that it sure didn’t look modular to me!
Another example is an organization that (for reasons) had VLANs touching three different locations, including the inside and outside VLANs for an active/passive pair of CheckPoint firewalls. I ended up creating a big ugly diagram tracking which links carried which VLANs. Pretty much every network device had to be in that diagram.
Their WAN provider had cheap but not very reliable links, so there would sometimes be flapping conditions destabilizing the VLANs at all three sites: one big failure domain. Fun!
We’ve been converting the network to routing between the three sites. The new diagrams will only have to show one site per page. That’s a good indication of modularity: when you can diagram a module and put in a couple of links, pointing off the page, indicating the links and routing to the next module.
Inside data centers, it is sometimes a challenge to stay modular and avoid getting everything all cross-connected. For instance, with SD-Access Transit, terminating site tunnels at the data center(s), it might be tempting to cable a Guest VN (VRF) directly to an edge firewall, rather than running the traffic through the fusion firewall, across the data center network, and then through an edge firewall. Creating a separate VRF across intervening stuff is an alternative, ensuring the guest traffic stays isolated. In some ways, the cabling solution is simpler, cleaner. But it creates an additional path and flow, an exception to the main pattern. Add enough “backdoor” links and troubleshooting, then requires more knowledge of the cabling and the “special traffic flows.”
Good Modularity
Here’s an example of a modular approach. Note the “core switches” in the middle serve purely to connect up the few optical aggregation sites, the SDA Transit tunneling head-end Border Nodes, ACI, the cloud connections, and the Internet Edge.
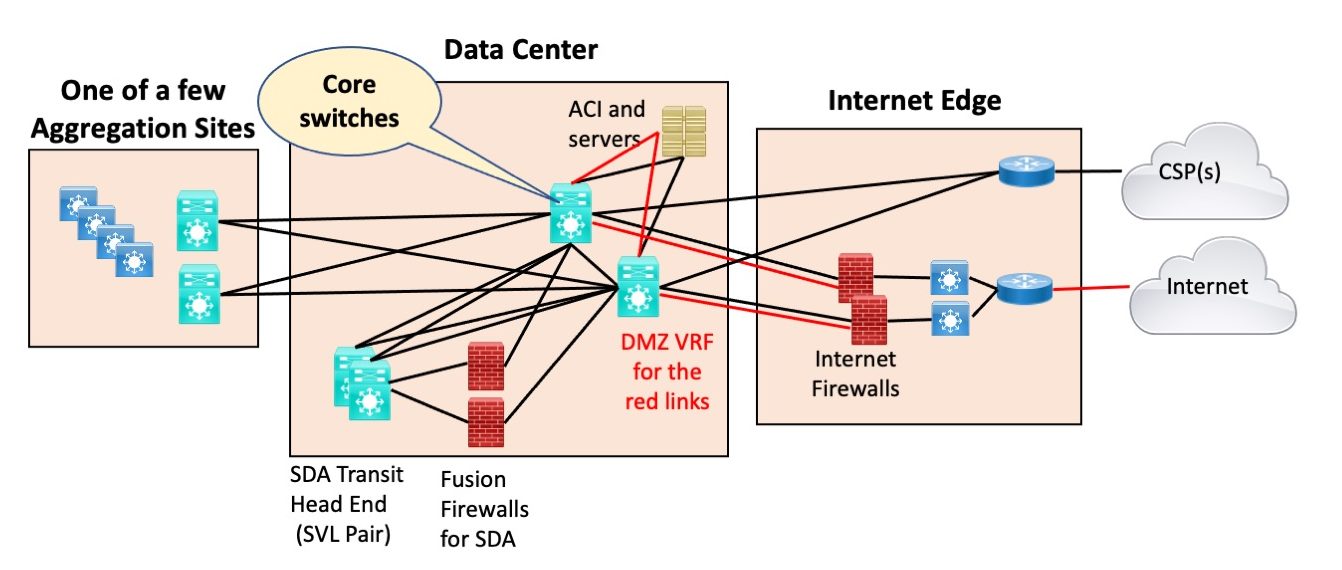
Detail not shown: ACI has the usual spine and leaf (attached to the middle switches via a couple of leaves). For this purpose, it is a box (module) off to one side.
There’s more stuff in the edge and elsewhere, but I didn’t want to clutter up the diagram and obscure the big picture.
You could perhaps make a case for having separate aggregation switches for the optical ring the Agg sites are on, but the cost didn’t seem justified. There’s a second data center with a similar structure, so there’s lots of redundancy and physical diversity.
Keeping Boundaries
Messy module boundaries can happen in other ways. For the above network, in an SD-Access design doing SDA Transit, we’ve designed it to use fusion firewalls. Given the volume of traffic, they’re rather costly.
One alternative might have been to use the ISE / ACI integration to use the ACI fabric as a sort of giant fusion firewall, coupling remote sites that tunnel to the data center to the innards or the datacenter, etc. If it helps, this conceptual design would basically consider ACI as a sort of combination giant switch and firewall (policy enforcement tool).
Here’s a diagram of that:
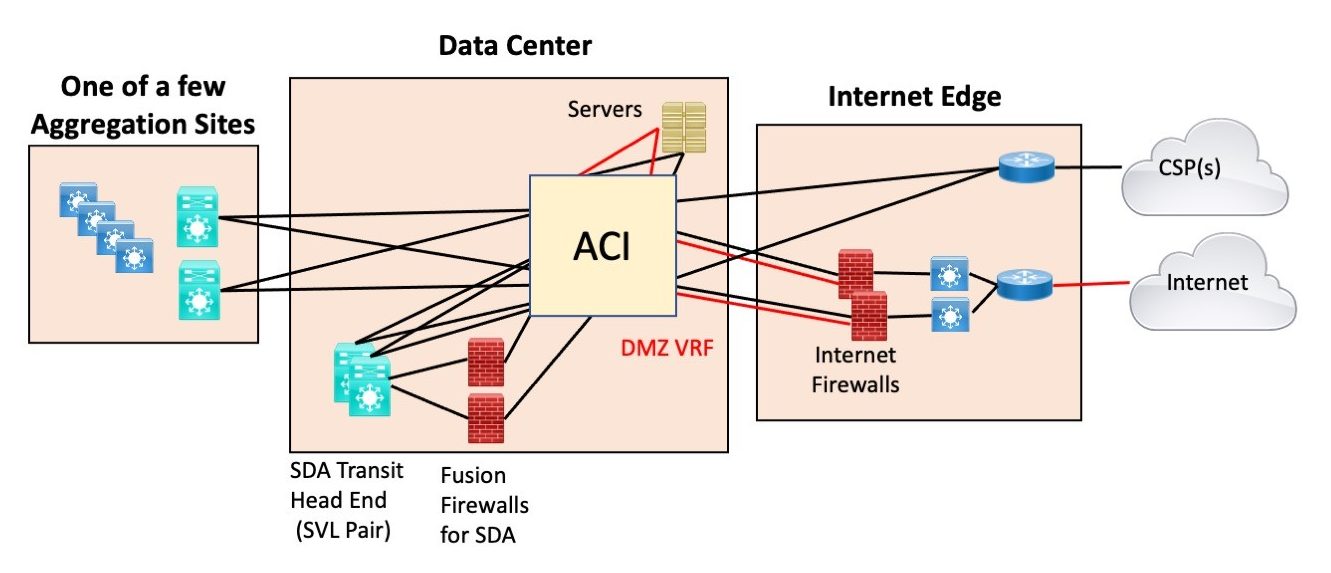
The issue with this: doing this ties two or three datacenter components much more tightly together with compounded complexity and shared fate.
Also, where do you draw the line? Do you also use ACI to connect all the servers to the firewall and the firewall to the border router? You could.
I prefer creating a boundary there and separately cabling to the firewalls, any “outside” switches, and the border router(s). I have seen a design where ACI and VLANs were used to connect the insides of various firewalls and other external connections to each other, the one giant switch approach. Let’s just say, the structure of the security boundaries was not readily apparent. Tough to do an audit?
I can imagine something similar coming up if you’re doing your server firewalling inside VMware and want to connect your DMZ VMs and associated VMware firewalls directly to the Internet border router, rather than handling DMZ to Internet traffic on a physical firewall.
(For a diagram, take the above diagram and mentally re-label ACI as VMware.)
Is that a good idea? Where do you firewall your user traffic?
One answer is: put a separate physical or virtual firewall in the path between users and the border router. The border router then could have two inside interfaces, one (or more) connecting to VMware and servers, the other to the user firewall. If the user firewall is virtual, then you’ve inserted VMware in the user to Internet path.
Is all that a good idea? My answer leans towards “no” on the grounds that separate devices are in many ways “less complex.” Nexus 7K VDCs can at least be treated as mostly separate devices – until you have to do an upgrade.
Yes, opinions may vary on all this. My concern is the “I have a hammer” problem. A hammer is a great tool. But that doesn’t mean it’s a good idea to use it to solve every problem.
Messy Modularity
Now let’s look at an example of a messy boundary.
The site in question has a campus built on older technology. I’ll call it a fabric technology since it does use tunneling. There are two data centers.
I’ll hasten to add that the site is aware of the issues I’m about to describe and has been working to fix them.
Servers previously were attached to fabric switches in the data centers. As things evolved, servers became VMs on a UCS chassis attached to a Cisco Nexus switch. However, the connection from the Nexus switch to the fabric switch stayed in place.
The firewall also used to be connected to the fabric switch, which made sense at one time. That connection never got moved to the Nexus.
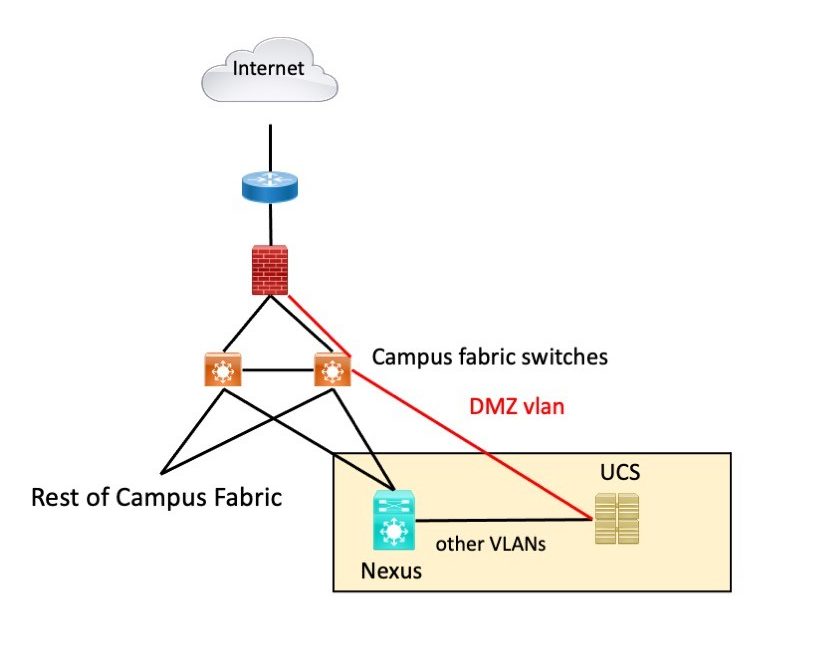
Result: complexity. It works, but the data center is not isolated from campus fabric events, routing, etc. Multiple tools are required when troubleshooting. The term that comes to mind is “friction” – everything is harder, slower. Oh, and if the fabric breaks (there’s a lot of L2 switching), then the data centers break.
Something like this used to happen a lot in the Cisco Nexus world. “Gee, I have this big Nexus 7K switch with a gazillion ports, so let’s do VDC and connect everything to it.” I’ve come to prefer physically separate devices – less shared fate, less apparent complexity. (It does help somewhat to treat and diagram VDCs as separate devices. Good naming also helps. Do avoid long VDC names!)
Conclusion
Well, that’s a long list of stories and lessons learned. I hope that saves you some painful learning!

