
I recently posted a blog about the prior blogs I’d written about SD-Access/DNA Center design and some implementation details. My intent there and in this blog is to update y’all with some more recent discussions I and others have been having.
More recently, I/we also posted an update about SD-Access (“SDA”) Sites.
One other topic seems to keep coming up, both in an SDA context and in a general context: the Internet connection, which everyone seems to do differently. And sometimes poorly if the intent is High Availability (“HA”). Maybe we should call it “The Kluge Zone” (with eerie music accompanying it).
For SDA, this can be a deep design topic if you’re using SDA Transit.
Single exit is fairly simple. It has to be. LISP will provide what amounts to a default route saying, in effect, “to leave SD-Access land, tunnel traffic to this Border Node (or HA pair).” That tunnel generally terminates in the data center in fairly close proximity to your Internet exit path. If your data center has other stuff (like a site or two) between it and the Internet exit, that may need extra thought. That situation tends to be rare (or I’d like to think so). And the considerations described below still apply. With SDA Transit, you still get to pick one or more default exits, which might be your Internet blocks or your data center blocks, but it can’t be both.
When you have two sites providing Internet exit, things get more challenging. If you want failover, there are some simple but non-obvious ways to build it.
A feature I’d long awaited from Cisco called “border prioritization” was built but reportedly has been buggy for a while. The idea (as I understood it) was to be able to specify the border site you prefer for Internet egress, with failover to the other site. The last I heard was work is being done to fix that and that a feature called local over-ride may be coming sooner that might be relevant. Both features don’t come up in Google or Cisco search, presumably since not officially supported yet. You’ll need to talk to Cisco SDA experts if either of these features sound interesting or necessary for your design. I’m certainly in no position to talk about internal Cisco work in progress.
Late update: Cisco HAS been talking, e.g. at Amsterdam, about a priority feature: think overall primary and fallback exits.
Since this was first drafted, I’ve found out about a brand-new Cisco feature for SDA called “Affinity”. It was apparently announced in October 2022 and was apparently too new for CiscoLive Amsterdam. I’ll post a separate blog about it as a follow-on to this one. If this is urgent for you, talk to your Cisco TME.
So, what can you do with well-established and familiar, trusted technology?
How Do I Support Dual Exits?
All is not lost!
With a modicum of high-speed interconnection, you can get a substantial degree of multi-site high availability fairly simply.
The simplest answer is arguably to run IP Transit. AKA “VRF-Lite on all underlay links”. Not too bad if you have only 2-4 VNs/VRFs. Messy if you have more.
What that buys you is the ability to choose which prefixes and metrics to use to direct traffic to where you want it. I like BGP for that, myself. Link state protocols like OSPF and IS-IS make traffic engineering a bit harder.
Dual Exit Diagram
Here is a new, improved version of a diagram I’ve used before, made especially to discuss this situation.
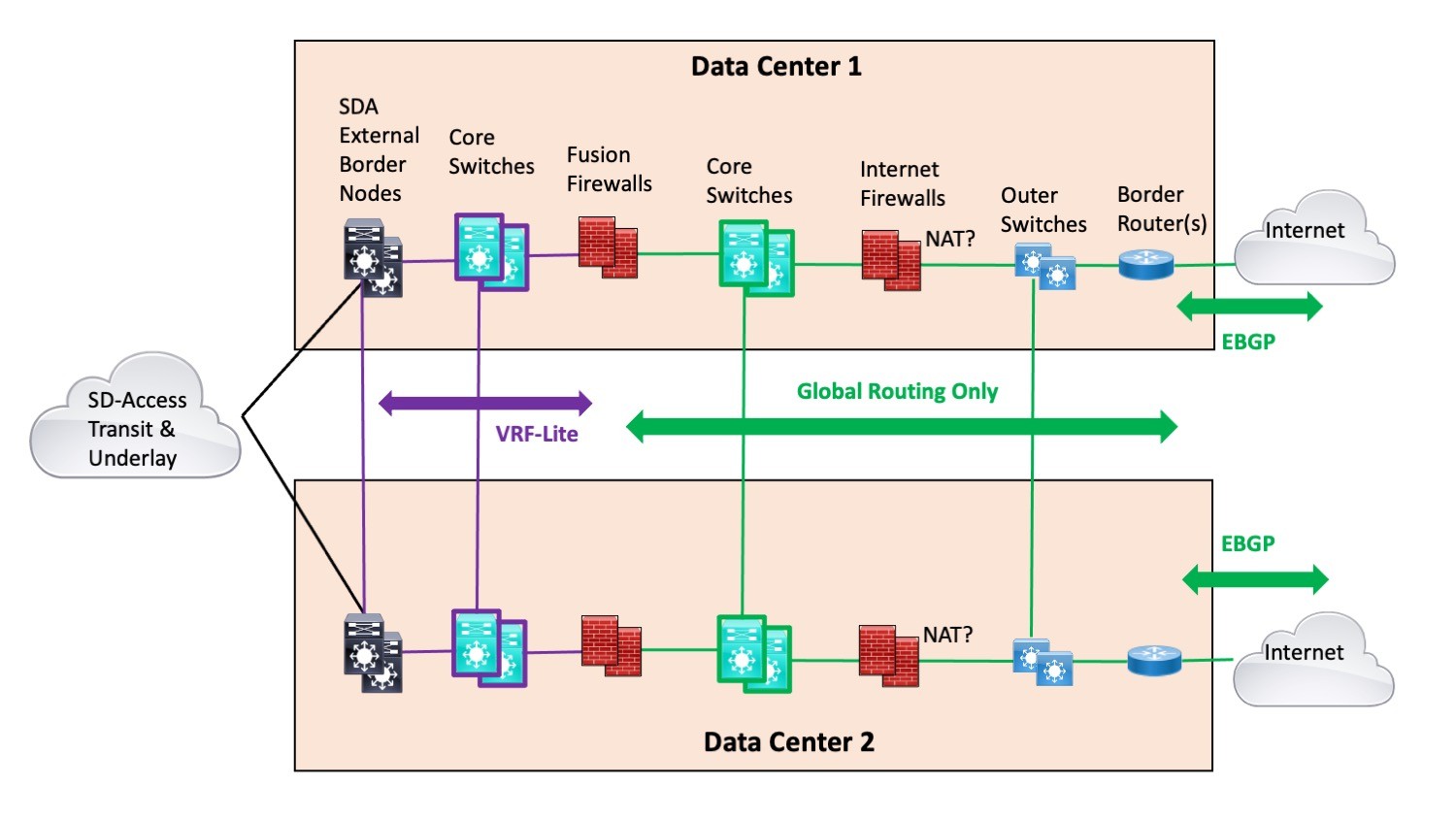 Note: I drew single lines to reduce clutter. In actuality, the vertical pairs at the two sites would be connected by two or four cross-links (“rectangle or bowtie”). For that matter, the horizontal links (lines in the diagram) would also be two or four links.
Note: I drew single lines to reduce clutter. In actuality, the vertical pairs at the two sites would be connected by two or four cross-links (“rectangle or bowtie”). For that matter, the horizontal links (lines in the diagram) would also be two or four links.
The idea is to run SDA Transit into two pairs of “External Border Nodes”. One pair in each of the two data centers: shown on the left above. The purple highlights where VRF-Lite is running (or “IP transit” – I avoid that term for this localized case since it seems to add unnecessary obscurity). The VRF-Lite runs into the left side of the Fusion Firewalls (“FFWs”). Everything in the FFWs and to their right is global routing only.
The purple core switches are just VRFs on the same physical switches that are shown with green highlights. Or they can be separate switches if that makes you feel better, you want simplicity, or you like contributing to Cisco’s bottom line.
I draw the diagram this way since everything else I’ve tried ends up with triangles in it or just looks weird. (E.g., stacking the purple and green core switches in the diagram.)
Why do it this way?
Well, the key point is that it de-couples the SDA network from the firewalls and edge. Basically, SDA Transit gets your traffic to one of the data centers, and if there is a firewall problem, you can shunt the traffic to the other data center, and back if necessary/desired.
The design issue at play here is maintaining firewall state for flows and return traffic. Especially long-lived flows.
For this design, I would run BGP on the FFWs, so that if there is a problem, routing on both left and right sides will shift stateful traffic to the other site. (Details left to the reader.)
You then have the choice of running with a preferred site or not. Since the FFWs can require a lot of capacity, they may be costly, which will create the urge to use them. If you choose to do that, you have all the usual routing tools to work with, rather than having to depend on SDA features that may not exist or are new and possibly buggy.
LISP Pub/Sub
My understanding is that SDA LISP Pub/Sub at present gives you the ability to designate Internet exits, and round-robins if there are multiple such sites.
The above design with its decoupling lets you have dual site HA and “fix” the routing to do what you feel you need. Single preferred exit for simplicity, or dual with more complexity.
About the FFWs
It seems like I should include a reminder about what the FFWs are there for.
Their primary purpose is to control traffic going between VNs/VRFs. That’s presumably why you created the VRFs in the first place: you wanted to isolate guests, IOT, PCI traffic, whatever.
The second purpose is as one possible point to control user to server access, a common need unless you’re maybe doing ACLs in some form in VMware NSX. Or less commonly, ACI. That’s also probably how you filter server to server flows.
Generally, sites I’ve seen already have an outside firewall pair, controlling server to Internet traffic, and usually user to Internet as well.
Failure Modes
Assuming reasonable routing, etc., a single device failure or single link failure shouldn’t be a problem. There’s a LOT of redundancy there!
Let’s examine some failure modes.
- External border pair failure or cut off from underlay at one site.
IP Transit or LISP Failover would be needed. IP Transit would be your standard IGP or BGP failover.
LISP without Pub/Sub seemed to NOT fail over, or at least only very slowly, the last time I tested it. LISP Pub/Sub is new since the last time I had the opportunity to do testing.
- Border pair to FFW, FFW, or FFW to core switches failure.
With dynamic routing (with the FFW participating), traffic should go via the other data center. If you have a preferred exit via the Internet at the data center with the failure(s), traffic should go back across the crosslink, etc. (Sub-optimal, but beats playing games with, or waiting for Internet failover?)
And if you look closely, the whole FFW block story becomes the same as the core switch/Internet firewalls/outer switches (or routers) story, as far as routing and failover.
In short, this approach de-couples how the packets get to one of the data centers (IP Transit or LISP-based SDA Transit) from the whole firewalling and Internet routing situation. Which is a good thing. Modular design, reduced complexity.
But!
Note that the above assumes the two exits are relatively nearby, so that latency is a non-issue. If they are far apart, then you’ll probably want location-aware exit priorities, which is a summary of what Affinity can do.
What I can’t easily tell you how to do is obtain load-sharing across exit complexes. The challenge to load-sharing is preserving firewall state. Policy routing based on source IP block seems like it might be turned into a workable solution.
If you’re willing to do cross-site firewall clustering, then stateful return paths is no big problem. I’m game for localized firewall clustering, but cross-site clustering strikes me as adding complexity and risk (new failure modes) rather than increasing availability.
Yeah, it would allow use of the secondary site devices and links, neither of which is likely inexpensive.
Drawback: if the cross-links fail between sites, you still have a problem. Put differently, adding cross-site failover to a routing scheme that uses both Internet exits statefully adds another increment of complexity. Do you really want to go there?
Late Note: Affinity seems to help address this!
Variations on This Theme
Static routes – just say no.
If you use public addressing internally and do NAT on the firewalls, to two different public blocks that are externally advertised (i.e. 2 x /24 at a minimum), then that potentially simplifies state preservation. Advertising a /23 and one of the /24s out of each site might be useful in that case.
I don’t have any other ideas at the moment. Especially ones that avoid complexity.
Need More Control?
It’s less elegant, and probably more configuration work, but IP Transit could be a serious consideration here. Especially if you don’t expect to have more than a couple of VNs (VRFs) in your SD-Access network. (Be sure, because later on changing from IP Transit to SDA Transit seems like it would be painful?)
What that buys you is a bigger set of routing tools for which traffic goes where.
Conclusion
I hope this gets you thinking about your Internet exits and redundancy, and what your failover strategy is.
I’ve seen a lot of designs where Internet dual-site automated failover hasn’t been implemented, or only works for some failure modes. Also, I and others used to not trust dynamic routing on firewalls (or not trust the firewall admins), perhaps due to painful CheckPoint experiences. But all that may have changed without us noticing!
Thanks to Mike Kelsen (and J.T.) for discussions and insights around this topic.


