
It’s time for a change of topic! Enough of that (Internet) Edgy stuff!
This blog describes a miscellaneous set of tips and tricks that might make your networking life easier. In particular, I include some things you can do to make the network easier to support.
Layer 2 Bypass VLANs
One slick idea comes from a customer site. I’ve generalized it a bit.
The basic idea is that if you have a Layer 2 inline device like a load balancer or WAN accelerator (dated example) that occasionally locks up or gets squirrely, you may want to be able to “take it offline” without physically recabling things, and reboot it that evening, say.
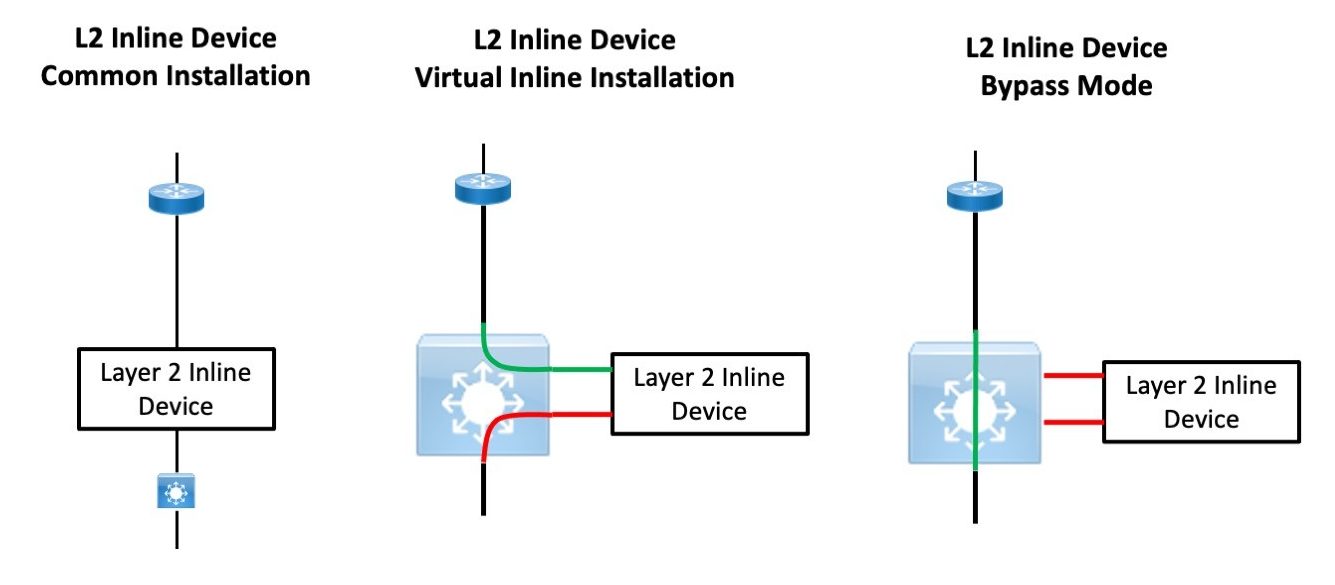
The idea is that you use inside and outside VLANs tied to the same subnet at the ends to connect the L2 devices. To bypass, you just change the VLANs on the switch ports to bypass the L2 devices, as shown in the right-most part of the above diagram.
This does assume we’re working with untagged traffic and manipulating the native VLAN on the ports in question.
Dot1q Tag Awareness
While we’re on L2 inline devices, I’ll note in passing to beware of inline boxes that have to be configured to properly handle 802.1q tagged traffic. There is at least one vendor of load balancers that promiscuously forwards dot1q VLAN traffic stripped of the tags. It does that if you don’t tell it that the port is a trunk.
This does interesting things when adjacent to a Cisco ASA that blocks traffic seen arriving on the wrong interface. It learns that some traffic came from outside, then it sees the outside source IP as the source of something on its inside interface. And blocks it, totally, both the correct and incorrect versions of it.
Fake vMotion for a Lab
This idea is something I came up with for a Proof Of Concept lab where we needed to simulate vMotion with L2 Data Center Interconnect (DCI) between data centers. I used this with some LISP testing a few years ago to verify LISP would respond properly to the VM’s new location.
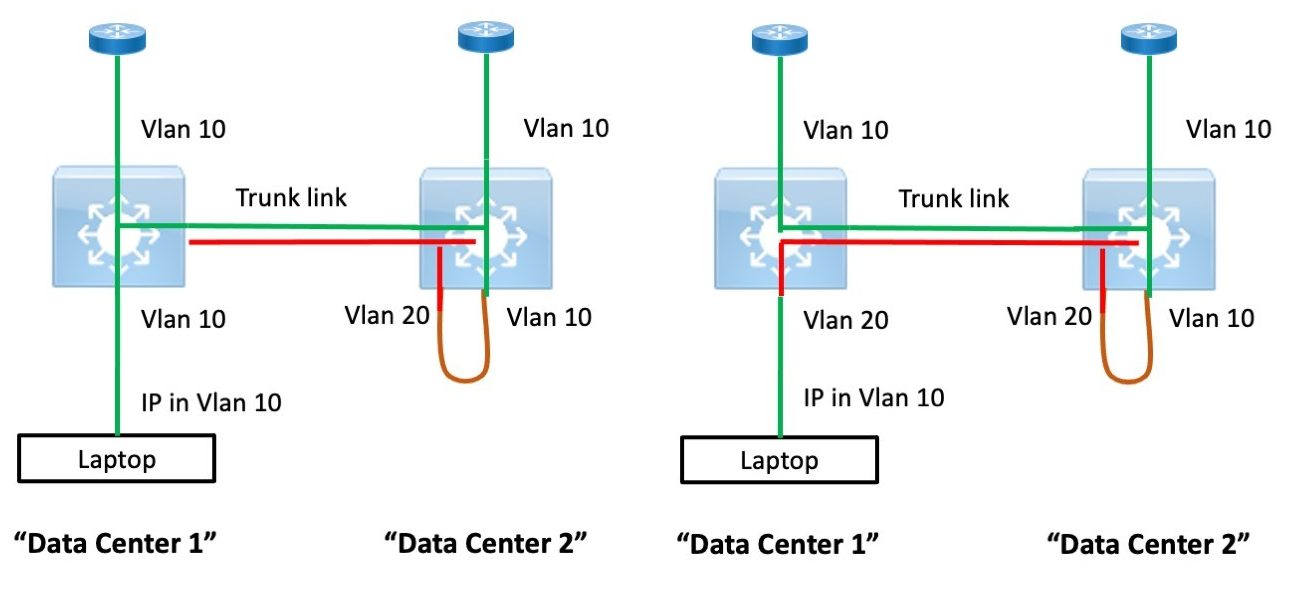
The idea is that you change the port the laptop is connected to from VLAN 10 to 20 on the left switch, as shown in the right half of the above diagram. From the perspective of the switches and VLAN 10, the IP address of the laptop is now connected to a VLAN 10 port in the right switch.
This doesn’t precisely mimic what happens with vMotion (I’m thinking gratuitous ARP, also impact of port VLAN change on MAC table), but it pretty much sufficed for the lab testing. (As in, better than nothing.) I wanted to avoid a cabling disconnect/ interface down / new interface up event. And also moving from where my laptop was into the data center to (slowly) move a cable between ports.
Gigamon as Security Patch Panel
This is something a customer was doing: an Internet Edge switch was configured, so the inside and outside facing ports were connected through a Gigamon. Various security devices were connected to the Gigamon. This allows traffic to be steered through the devices by the Gigamon, redirecting or copying selected traffic to security devices as needed.
You can extend that to make the Gigamon a virtual patch panel, in effect. Plug inside and outside switches into it and use the Gigamon to build a path between them via firewalls and other security devices.
The one potential drawback is complexity / documentation / cross-team communications. Without that, troubleshooting by the network team is a problem if there is a lack of visibility into what the Gigamon is doing.
See also my prior blog about Gigamon and MITM decryption for SSH/HTTPS.
Loopback Testing in a CoLo
This one may fall under the heading of “don’t let the CCIE near the cabling.”
A customer was having new cross-connect connection problems in a CoLo. Multiple teams were involved, including NetCraftsmen, customer, CoLo provider, and ISP.
We tried turning on optical loopback at each hop in the path, working carefully from one end to the other. Also checked the patch cabling was correct (single mode) at every hop—no problems with light levels, etc. But the customer router link wouldn’t come up. Shut / no shut not changing anything.
We finally rebooted the router since we couldn’t think of anything better to try. The link came right up.
Lesson learned: it might not be the cabling. Even Cisco routers do occasionally “get stuck.” Rebooting and crossing your fingers is not high on my list of Cisco troubleshooting techniques since rarely needed. But the lesson learned is to try it before you reach the “what the heck else could be causing the problem” stage and hours of expended time. In fact, given the joy of coordinating all the teams involved, it might have been a lot faster to have just rebooted the router upfront.
Don’t Invent Extra Numbers
If possible, number an L3 router subinterface with the number of the associated dot1q tag. That is ethernet 1/5.200 matches with dot1q tag 200. And do make sure that subinterface N matches up on the two ends (talk about confusing ways to build things: putting different dot1q tags on the two ends on subinterface 2, say?).
I’ve done the same thing with parallel tunnels (same endpoints) supporting SD-Access VRFs (VNs) and tunnel keys.
When connecting two devices with a port-channel, use the same port-channel number at both ends if possible.
When using a pair of devices, use mirror ports where possible. That is, if you use Eth 2/3 to connect to device Y on switch A, do the same on B. Reserve a range (at the high end of the ports, perhaps?) for the singly connected devices.
For that matter, when building out dual data centers, mirror them as much as possible. If you can, do that down to the interface IP level, i.e., different prefix but same last octet/subnet mask. (Thanks and a tip of the hat to our Mike Kelsen.)
Document Thoroughly
It’s not just diagrams and documentation. Which I firmly believe are necessary, but don’t go off the deep end. More and more tools provide diagrams on the fly. What they usually do not do is provide a high-level diagram summarizing for human learning/overview. And they certainly don’t provide 2, 5, or 20 pages of words describing the network at a high level. And why you did things a certain way, particularly if it might be viewed as a bit “weird” or complicated.
DNS is valuable too. Don’t scrimp on it. The time you put in upfront will repay you.
I’ve worked with two sites recently where every (or most) interface is in Infoblox with consistent naming. So Device FOO-BAR is reached via FOO-BAR-MGT (or mgmt). And its interfaces are FOO-BAR-ETH1-3.2 etc. That makes traceroute really easy to read. And having consistent naming for management ports helps a lot too.
Belt and Suspenders
Most sites have some in-band or out of band management connectivity, usually one of more management switches. Useful for device upgrades, high-speed CLI access, etc.
But a terminal/console connection can be darn helpful, especially when you work remotely (more WFH these days?) and a box needs a reboot or something. Just recently, I botched a boot system command, and the switch needed a console connection. Someone had to go to it and jack in. In another case, a switch upgrade to “install mode” failed to correctly set the boot system variable. In both cases, in Cat 9K switches, it appears that having the boot system command set to flash: and no filename does not fall back to finding a .bin file or package.conf file to boot off of/with. (Sigh!)
On the topics of console servers and out of band management (OOBM), see also my #NFD26 blog about ZPE Systems. Or visit OpenGear or Raritan’s websites.
Avoid Needing to Do Cable Tracing
Just enable CDP and LLDP everywhere. It sure beats having to manually trace cables, which will happen at the worst time possible when troubleshooting, per Murphy’s Law.
Oh, and consider a CDP or LLDP agent on servers too. Worth the effort!
Yes, you don’t necessarily want to run CDP/LLDP on the outside of your organization. On the other hand, does doing so really expose much of anything? And would the organization at the other end notice or care? That is, how much risk is there if you leave CDP/LLDP enabled on an “outside” connection to a provider of some sort? Sure, shut it off on the outside; it can’t hurt. But really?
I personally would strongly like the ability to enable CDP or LLDP on the inside of firewalls as well. I’m not holding my breath on that one happening!
Another pet peeve is L2 devices in general. I much prefer L3 firewalls since at least I have some indication they’re there. The issue here is that I’ve been repeatedly burned as a consultant because a customer didn’t tell me about an L2 device between point A and point B. “Burned” as in wasted some hours. When I ask if there’s something odd about the link, “oh, sorry, there’s a firewall in there.”
Self-Documenting Interface Descriptions
This comes under the heading of making the network easier to support.
I like descriptions to contain the current device name, interface name, remote device name, remote interface. And perhaps VRF at each end. In some formats, you can easily parse in python. A common separator character, perhaps ‘#’, for split() works. Note that it must not occur in the component names in the description.
For interfaces with CDP or LLDP, you can script generating the configurations for this in python without too much difficulty. It helps to do the same for non-CDP/LLDP interfaces. A python script could then easily build a spreadsheet of all connections out of each device, just from the captured config file. I’ve got such a script, which I’m using to diagram a network with VRFs and do some basic checking. Google search found at least one such script online. I was thinking of extending it to figure out connections via IP and MAC address info, but it’s faster to just figure out the firewall connectivity manually from the good descriptions. And IP and MAC in the presence of VLANs don’t always tell you direct connectivity.
An alternative approach and links can be found at https://shnosh.io/eem-cdp-description/. The script shown there detects CDP or LLDP changes and updates the local interface description. It also contains links to the prior history of such scripts. The main drawback I can see is perhaps that of pushing new EEM script versions out to devices. But hey, we’ve all automated that, haven’t we?
Limit Redistribution with Route Maps
Always always limit redistribution with route maps! And don’t work around Nexus with a placeholder route map-map unless you really mean it.
This item fits under “making the network easier to support” since not having an outage and troubleshooting route redistribution is inherently a major win!
I’ve spent a lot of time I wish I had back, doing route redistribution and then troubleshooting too much redistribution. Sometimes my own fault. I’ve come to describe redistribution as something every CCNP loves and is way too eager to do, and every experienced CCIE approaches with caution. It is especially risky when you have two or more points of redistribution. Or many sites with a somewhat random redistribution scheme.
So not only use a planned design and route maps but redistribute no more than you have to. If you have stub networks, just advertise the default route and/or corporate default into the stub site. Think “need to know.” Also, distinguish between learning a route and redistributing it. For instance, if a router pair at site A advertises a remote site X’s prefix to each other, no problem. But it should not be redistributed into external BGP or WAN routing because site A is not how other sites should be getting to site X. Only the local site A’s prefixes should, in general, be advertised out of site A. And with proper design, that is ideally one site summary prefix and not more specifics.
So more recently, I like to actually hard code that defensive route map into a site’s WAN routers to make sure it doesn’t accidentally somehow advertise more than it should. Simple at the time of buildout and eliminates potential strange routing issues.
A little forethought and organization here can save a LOT of time and fun troubleshooting. Also, having a lab or model of the network (VIRL, etc.) can really help with things like route redistribution.
I’ll note in passing that SD-WAN usually makes some simplifying assumptions and saves us a lot of this potential complexity.
Conclusions
That’s a somewhat random collection of tips, tricks, and thoughts. I hope some of it was useful to you!
![]()
