
NetCraftsmen is currently working with a customer with some interesting problems. I’d like to share some thoughts and lessons learned.
Cheap Is Sometimes Not
This first item is arguably obvious, but I suspect a fairly common problem.
The less-expensive fiber provider may not be a great choice if they keep having outages and packet loss issues. The network group will suffer reputational damage even if they didn’t make the decision.
Needle in Haystack
This second item is something that tools such as ThousandEyes, CatchPoint, Netbeez, etc., have enabled. The current name for this sort of product is Digital Experience Monitoring (DXM). Let’s refer to them as network probes, which is shorter if not as impressive sounding.
The common use case that the vendors push is monitoring WAN, Internet, and cloud connections and app availability. Monitoring can be from within your network or from a set of internet-based probe sites that the vendors maintain. All useful and even important.
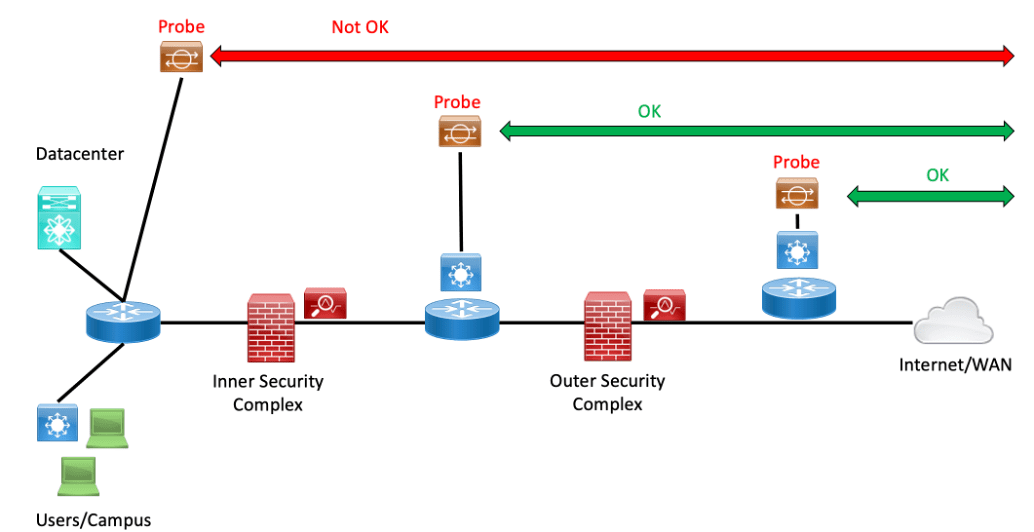
But there’s another potential use case. If your network has multiple firewalls and other layers between servers or users and the Internet or WAN, with some complexity in there, then when there is slowness, finding out where to focus your attention can be hard and considerably delay getting the problem fixed. I have an idea, perhaps obvious, about how to mitigate that somewhat.
I’ve written before about a version of this. As a reformed mathematician, I think of the general approach as a “bisection search.” As in, divide in half, see which half has the problem, divide that in half, and then repeat until you’ve found a culprit device or link.
Well, now we can do a fancier version. If you can obtain several small agent devices from your favorite network probe vendor, how about placing them at several points along the path to the Internet (or WAN)? I’d especially want one on each side of each firewall or security complex in the path.
Then your monitoring should tell you: it’s good from here out, but the next probe inwards is having problems. And then you know where to focus your attention.
What do you probe? Maybe your basic ping, but it is wise to include synthetic application requests to critical cloud-based applications like VoIP to Zoom, Skype, Webex, and perhaps some Outlook traffic. All these would be good things to leave running. Those applications tend to be more fragile and good early warning tools – “canaries in the coal mine,” if you will.
Many tools will help pinpoint problems along the entire path, but firewalls can and should limit this functionality. Hence, probe traffic resembling user traffic may be best.
What Else to Monitor
Network (and security) complexity keeps increasing. The good news is that network probes and management tools are more capable, and so we should likely be thinking about monitoring a broader range of variables. SNMP or telemetry, if possible, but that’s where you may need CLI scripting to get at the data. The “network probes” and likely other tools may let you run scripts to capture data.
I highly recommend pulling key data from your firewalls, load balancers, etc. Noting throughput and becoming aware of throughput drops can be helpful. But if you can do so, monitor the number of connections and half-open TCP connections.
Packets “eaten” (dropped) by the firewall won’t show up in your router/switch SNMP counters. Hence the need to do this separate form of data collection.
We’ve seen such data indicate an external DDOS attack where the firewall was the first device to get bogged down with external DDOS probes. More recently, we’ve seen such data with traffic from the inside, which might indicate compromised hosts or some other problem.
Conclusion
Each time you have a problem in your network, it may be helpful to think about a couple of things:
- What would have told me there was something undesirable going on?
- What would have provided data about where the problem might be?
I’m a big fan of using lessons learned to minimize pulling out clumps of hair and reducing stress from multi-day degraded network conditions. Also, incremental improvement is a good thing.
I wish you good luck with your efforts to expand what you monitor!