
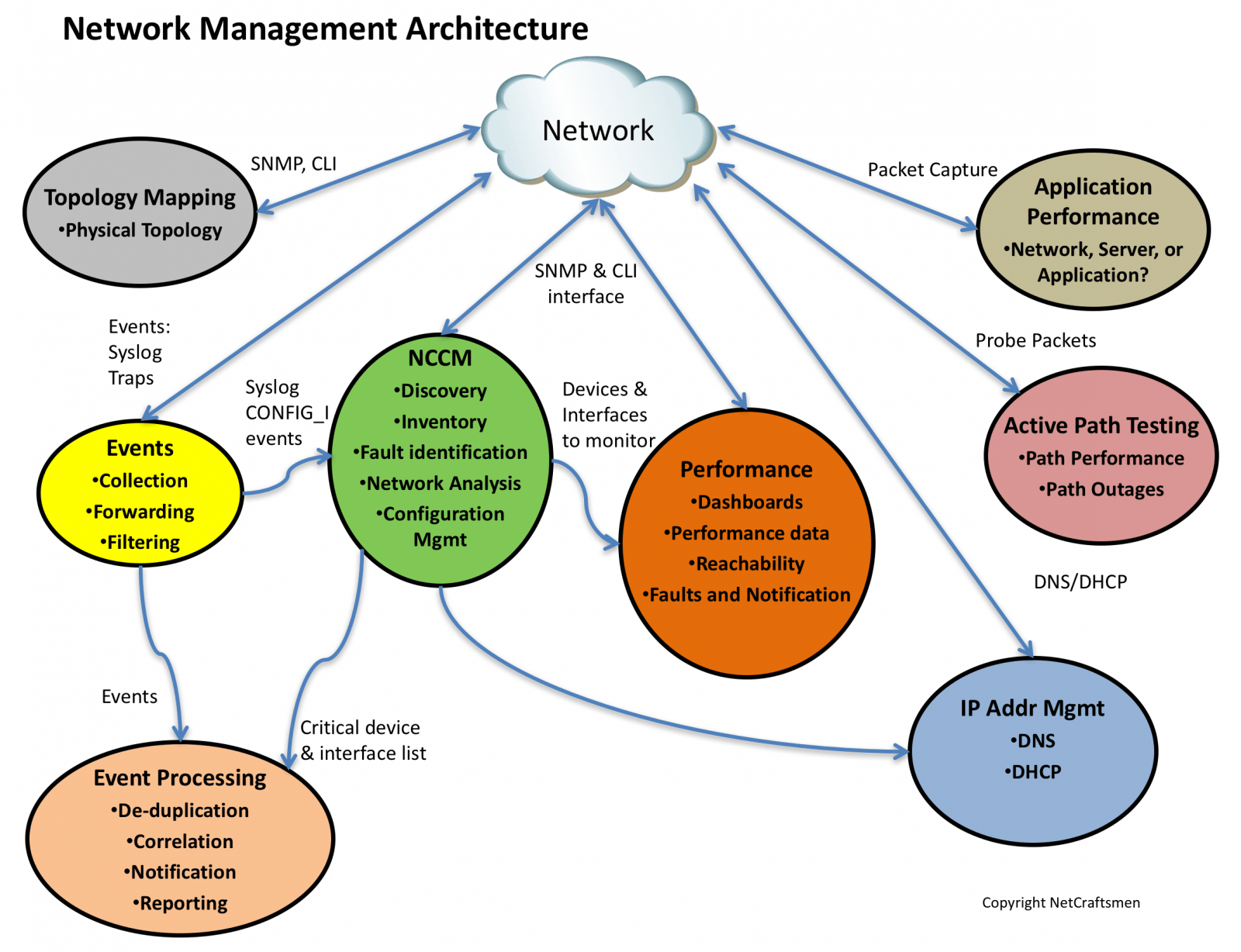
At NetCraftsmen, we get to do a lot of network assessments where we examine and evaluate a customer’s network, including the network management implementation. As a result of this work, we’ve identified a set of network management architectural elements. There are currently seven elements in the architecture, shown in the figure below. Each element provides a key piece of functionality that provides visibility into the network’s operation. There are multiple products that provide functionality for each of the elements, so you are not tied to a particular product.
Events
The first, and most important component, is an event collection and management system. It allows the network to report things that it is experiencing. You can think of it as the pulse of the network. Changes in the pulse rate or the types of events being received indicate a significant change that should be investigated.
Events are either syslog or SNMP traps, both of which are asynchronous events, different only in their formatting. Note that a Cisco 6500 has ten times as many syslog messages than SNMP trap messages, so syslog is the richest source of information. But don’t ignore SNMP traps, which are the only source of data from some devices. There are ways to convert SNMP traps into syslog messages, so that one processing engine can handle both.
Log processing of the stream of syslog/trap messages is key to avoid being overwhelmed with the message volume that a large network can generate. I’ve described a key mechanism here before, the syslog summary script and filtering events, both of which improve the management of log data.
NCCM
Network Change and Configuration Management potentially has the greatest opportunity for network improvement. Analysts who have studied this space report that over 40% of all network outages are due to human error. By automating configuration changes, making network configurations more consistent, and reducing the number of variations in network configurations, the network can be made much more reliable. The key function in NCCM is to track configuration changes and to store backup copies of all configurations.
Knowing what is on the network and collecting configurations from all that equipment is key to good change and configuration management. That’s why the NCCM element includes network discovery. You can only manage what you see. The network inventory is an is simple by-product of discovery, allowing easy verification of what devices and components to include in vendor maintenance programs.
We find that including analysis of the configurations is essential, both for adherence to organizational policies and to identify exceptions to industry best practices. Collecting some additional operational data allows the analysis to extend to the implementation. For example, we regularly find networks with very large spanning trees (VLANs). Organizations typically don’t think much of spanning tree scope or size until they have a serious spanning tree loop that takes out a significant piece of their network. We’ve had several customers experience extensive outages in the last year. A more serious example is described in an interesting CIO Magazine article “All Systems Down“. Cisco has a good article “Spanning Tree Protocol Problems and Related Design Considerations” that describes different types of failures, how to design around them, and how to troubleshoot an STP loop. You can’t determine how large a spanning tree implementation will be from the configurations – you have to look at the operational data in the network. That’s what NetMRI does better than any other tool that I’ve used.
I’ll describe the additional elements of the architecture in the next few posts.
-Terry
Other posts in this series:
Re-posted with Permission
NetCraftsmen would like to acknowledge Infoblox for their permission to re-post this article which originally appeared in the Applied Infrastructure blog under http://www.infoblox.com/en/communities/blogs.html.