
This is the fourth blog in an Internet Edge series.
Links to prior blogs in the series:
- Internet Edge: Simple Sites
- Internet Edge: Fitting in SD-WAN
- Internet Edge: Things to Not Do (Part 1)
This blog continues the previous one, covering more of the more interesting but undesirable things I’ve seen people do in the Internet Edge. My hope is that some strong opinions and some “real-world stories” may be of interest and helpful from a design perspective!
Bad Practice: Multi-hop Routing
Multi-hop routing pops up every once in a while. It usually strikes me as a bad idea, or at least sub-optimal. Yes, sometimes there is no great alternative. There are always exceptions to any rules or general principles.
There are two forms of multi-hop routing that come to mind: one is running routing over multiple L2 hops rather than a direct link. The other is usually multi-hop BGP.
The problem with the first of these is that when you have multiple L2 switches in between two routing entities, your routing is vulnerable to any spanning tree problem in the middle. A related potential problem is the size of VLANs and figuring out where they’ve been trunked to or why you’re having a spanning-tree problem – it’s a distributed troubleshooting exercise (also known as “slow, time-consuming”).
I generally try to confine any VLAN to a building or floor, or closet in a campus network and to a row or pair of racks in a data center. I’m a big fan of routing to the access layer! (VLAN span is one switch, no chasing down where the VLAN extends to.) I’ve had way too many not-fun moments tracing VLANs across a site, across a trunk to another site, and from there to a third site, etc. It takes forever! It also takes a good bit of effort to prune back such an extended VLAN, so they tend to persist. (Cleaning up static routes, sometimes ditto.)
Extended VLANs are also emphatically not something you want to have to troubleshoot in an outage (e.g., did someone add extra trunking to a VLAN, remove it from a trunk, etc.).
When doing design, I prefer to contain all campus VLAN sprawl up in a routed hierarchy to data center core switches, with routed links to any associated campus, etc. In short, the core/middle would be all routed, over routed links.
And L3 to the access layer for the big win!
The second form of multi-hop is probably more common: running EBGP multi-hop across a firewall. The reason I don’t like this is that you usually need some static routing so the two BGP peers’ BGP traffic can get forwarded between them. It’s all a bit ugly. Not terrible. The reason this evolved: firewalls used to be bad at routing (((plus weird buggy things with fanatical anti-social security admins who won’t let me access their stinking firewall no matter what … – ahem – bzzzt – END RANT – imagined network admin thoughts))). (Humor intended.)
Firewall vendors have been doing BGP for quite a while now. Mature code! For that matter, I recently worked with a CheckPoint in a lab, and it had an impressive set of BGP features. Still not a fan of CheckPoint. I’ll spare you why.
I’m not sure I’d do anything fancy with BGP on a firewall for fear of bugs, even now. Another potential issue: firewalls could have different administrators making access for troubleshooting difficult.
But simple EBGP should be workable, and if you don’t have anything to tweak in the firewall, well, BGP neighbor up / down does a lot of what you need. It’s still nice if you can negotiate to get enough firewall access to be able to troubleshoot (ping, traceroute, routing connectivity). Teamwork, not job security by control and with-holding information?
Here’s a diagram showing BGP via static routes to the peer.
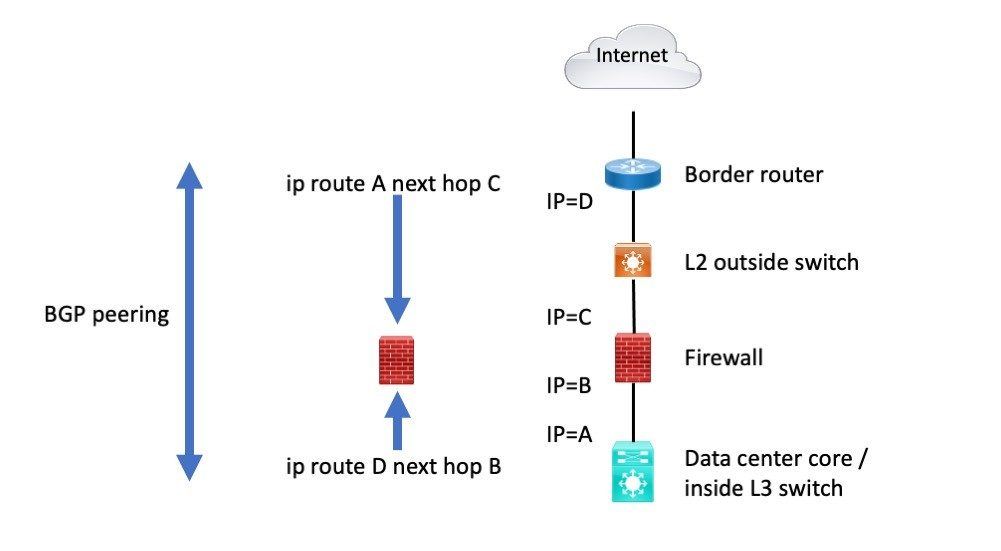
I’ll anticipate a later blog for a moment: I prefer running OSPF or EIGRP to the firewall for simpler cases. I like keeping BGP strictly at the edge if possible. If you don’t, it has a tendency to take over the core of your network. Doing so does offer a lot of control and filtering of routes, something OSPF certainly lacks. EIGRP has enough controls to be workable for what is usually needed.
That leads us to the next bad practice:
Bad Practice: Extra Egregious EBGP
So, you run EBGP from your border router to the firewall and from the firewall to the core switches. Oh, they’re in pairs. Do you give both pair members the same BGP ASN? Or different ones?
Extending to your WAN routers via more EBGP is the path of least resistance. It does save you from fun with IBGP and route reflectors, and EBGP does lend itself to fairly clean hop by hop peering and forwarding. But at some point, you end up discovering that EBGP ate your data center or even your network core.
I’m not sure I have an answer here. I know there’s a problem because working with such designs is like every day becoming a CCIE lab exercise but in production. That’s not where you want to be. Well, at least not where **I** want my design to put me.
One cause that I’ve noticed is that some sites use a separate router for each ISP, each type of WAN, each cloud peer. That’s very modular and redundant. But for getting routes back and forth between the routers, you end up with “a mess of EBGP,” or clumsy redistribution into an IGP and back to EBGP, or other ugliness. Adding in Anycast DNS via BGP /32 injection just makes it more … fun.
Here’s a diagram trying to illustrate what you might end up with. Firewalls omitted – this is already complex enough.
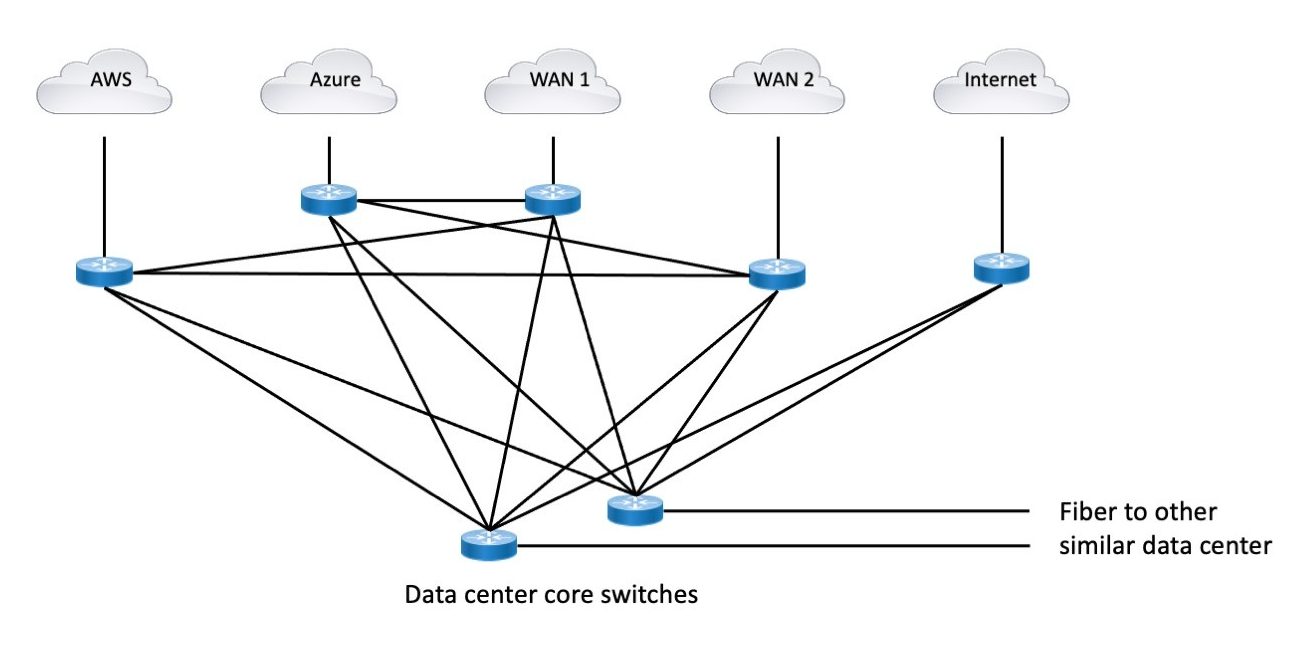
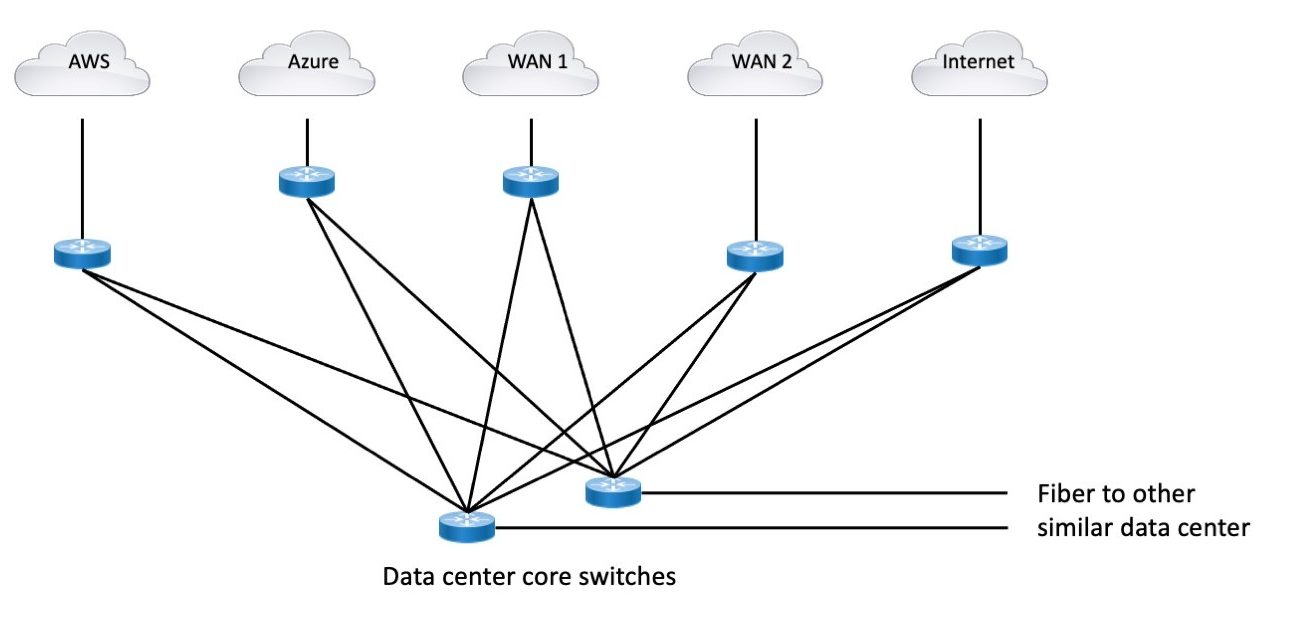
The first thing we could do here is to simplify the connectivity. The cleanest answer overall seems to be to have an EBGP pair that is basically routing hubs that every external BGP router or pair is peered to. And that hub pair then redistributes etc., to the campus cores. Otherwise, you end up with an ad hoc mesh (one letter away from ‘mess’). Routing policy in a mesh can get very complicated very quickly.
Is it possible that two border routers for N Internet links, and two WAN border routers for all the WAN and cloud links, might be a better way to structure things? Here’s what that might look like:
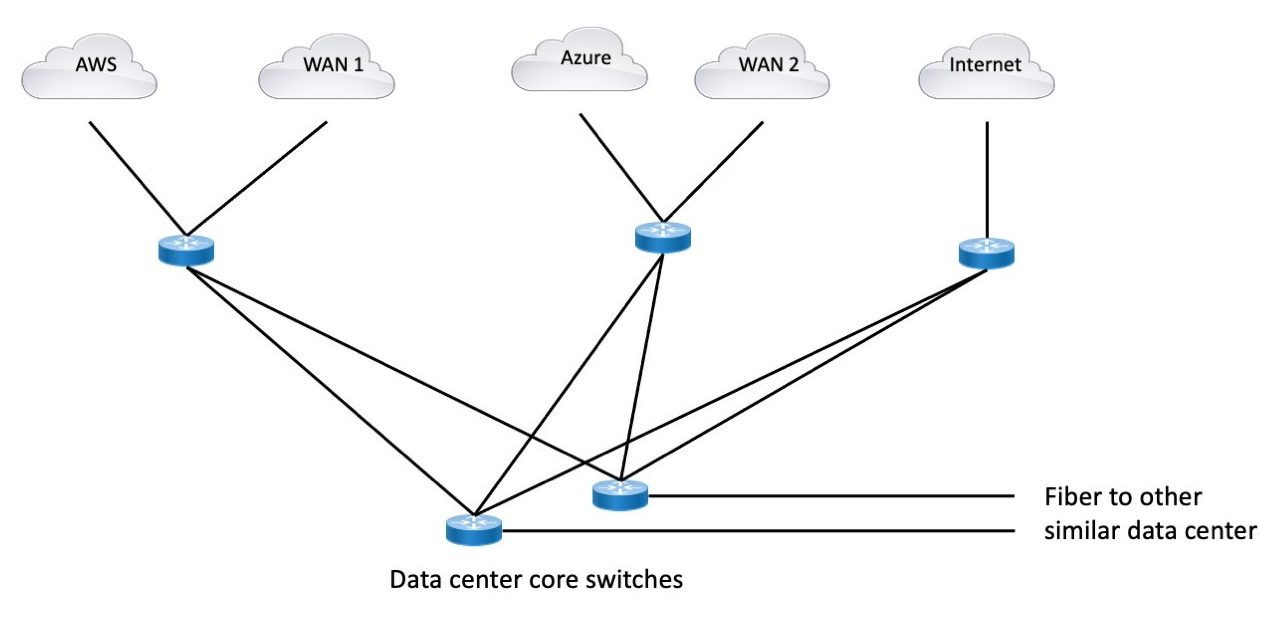
Single routers mean that when you add bandwidth, you replace that one router. Shared routers mean more costly replacements and is less modular in regard to the circuits – upgrading the router affects two circuits versus just one. Yet shared might be a good thing here.
That does depend on the security requirements. If the security team insists on firewalling each external connection, then the above diagram leaves no great way to put a firewall in between WAN1 and AWS or WAN2 and Azure.
VRFs? Yes, but a VRF is almost a virtual router, which puts us right back into the ‘meshy’ diagram first shown.
If you have an ad hoc design with several Internet and WAN and Cloud routers, oh, and firewalls and VDCs, well, you have my best wishes (while I run the other way). And for some reason, this is usually accompanied by an ever-growing mess of static routes (‘cuz firewalls).
By the way, if you have two data centers, then there’s also the topic of how the EBGP in one of them connects (via EBGP, of course, probably over DWDM or other dedicated fiber) to the other data center. But that’s a later blog in this series.
Bad Practice: Overly Fancy Edge BGP Features
I’m going to save this topic for a later blog about traffic steering or engineering etc.
In general, the more edge BGP devices, Internet circuits, and fancy things you’re trying to do with them, the more complex things will get. Consider having, say, 6 Internet links across one or a couple of sites. Say some are 1 Gbps, and some are 5 Gbps burstable on 10 Gbps physical. How do you make good use of all that for inbound traffic? And outbound?
The challenge here is that while BGP has lots of “knobs” you can use for routing policy, to some extent, they are rather crude controls. So, you can only do so much with them.
There’s also the 4 AM rule: If it takes a CCIE to understand it and the company CCIE is you, you WILL be woken up at 4 AM more than you would like.
Bad Practice: Web Proxy Over-Riding Routing
I ran across something different at one site. I’ll simplify the story to keep this short. There were four or five Internet-connected sites, with all the trimmings. I thought I understood the Internet routing. It didn’t match the traffic levels. Come to find out, all the PCs had centrally controlled web proxy configurations, and the deployed web proxy configuration sent all sites’ user traffic to the HQ WAN proxy devices and out that site’s HQ Internet links. In some cases, across the US.
Lesson learned: tunnels can override normal routing.
The second lesson learned: edge web filters should probably deal with any exiting traffic that gets to them via normal routing. It’s not good to have invisible tunneling that overrides routing.
Side effect: VoIP behaved differently than web / other user traffic if / when it was correctly excluded from the web proxy policy. Which might not have been consistently the case.
I recently blogged about SD-Access and SD Transit tunnels, which do tunnel site traffic back to the Internet exit Border Nodes. So, am I a hypocrite? No. Because that tunneling is for a campus-like (low latency) setting, and the tunnels approximate what routing would do anyway in getting site traffic to the data center and the Internet exit.
Bad Practice: Wide Firewall Clusters
Clustering seems to be becoming the in thing for firewalls, presumably in part to increase throughput by having Active / Active pairs or more. And sell more firewalls?
At one site, fine, maybe some potential “interesting” failure modes. Clustering across sites???? I think it highly unlikely I’m going to do that as part of a design. It could have VERY interesting (tough) failure modes, less stability? And shared fate.
Recent Practice: Cloud Security Tools via Tunnel
ZScaler, Cisco, and possibly other vendors have security solutions that entail tunneling some / all Internet-bound user traffic to them.
Tunneling Internet-bound traffic to a managed security offering is rather handy if not essential for smaller organizations, who cannot afford all the in-house security staff they’d like to have or need to do it themselves. It also makes consistent security available no matter where the worker is. Great for branch offices.
For what it’s worth, I’ve seen a case where a site had slowness with zScaler. It turned out the HQ router couldn’t handle the full tunnel volume of traffic during peak periods. Using web proxy solved that, shifting the load to the workstations.
With SD-WAN, the router is all about tunneling, so the aggregate throughput number may well include tunneling to a cloud security vendor.
This is just something to be aware of. Usually, such tunneling is distributed per remote SD-WAN site.
But if you’re doing it in a combined HQ and data center for significant amounts of user traffic, it would be a good idea to keep an eye on the volume of such traffic.
Lessons Learned
The following is my list of lessons learned, trying to sum up things as design principles. If I missed anything, please add a comment to the blog!
- You can always make it more complicated. Don’t.
- Corollary: It always even harder to remove complexity. So inertia usually wins.
- Do not split up a single site’s Internet Edge functions across multiple places within the site.
- Do not separate the Internet Edge from the rest of the data center by some other module.
- Have a modular design (tempered by size of your network) and do keep the key modules cleanly separated by routed links: Campus, Data Center, Internet Edge, WAN / SD-WAN.
- Dynamic routing is cool and very helpful: it tells you about whether the path to something remote is alive and whether that other something is alive. Static routes don’t do any of that.
- Don’t do multi-hop: routing hops should reflect the topology.
- Route to the FW (BGP or OSPF probably, unless it is Cisco).
- Control freak: route-maps on BGP in and out and on any redistribution. Avoid surprises!
- EBGP is generally preferred over IGP routes. So be careful with what’s in an internal EBGP.
- If you have two border routers, filter to not learn outside prefixes from an inside IGP peering, and vice versa. It is better to peer via IBGP. From MPLS days, BGP’s failure recovery doesn’t work when you learn outside prefixes via your IGP and redistribute them back into BGP.
- A planned set of prefix-lists by remote site with good names etc., can really help with filtering and routing policy.
- If possible, use ONE routing protocol except for handoff points (e.g., BGP at edge and EIGRP or OSPF internally, or OSPF for non-Cisco FW to EIGRP internally).
- Do not overlap routing protocols if at all possible.
- Know your security tools and network devices:
- Tunnel and crypto capacity: get all the perf stats you can from the vendor BEFORE you buy.
- Firewalls are notorious for grinding to a halt as you turn on all the lovely features they marketed to you. I’d love to see fair disclosure of what the per-feature performance hit is prior to the sale.
- In general, anything that does per-packet processing in the CPU is going to exhibit that sort of behavior.
Conclusion
Well, that’s a long list of stories and Lessons Learned. I hope that saves you some painful learning!

