
This blog is one of several about #NFD16.
Veriflow was kind enough to provide me with a demo and discussion earlier in 2017. I followed that up with the blog post, “Network Verification with Veriflow.” This blog post provides some updates based on what was covered in Veriflow’s #NFD16 presentation. If you like the idea of pre-validating and doing network assurance, or if you’d like more details, be sure to watch the streaming video of the Veriflow presentations and demos!
Quick positioning regarding Veriflow: interesting product; nearest competitor I know of is Forward Networks, which presented at the prior #NFD13.
Veriflow highlights the following capabilities:
- Continuous verification of network availability and resilience
- Continuous compliance and mapping
- Assured secure segmentation
- Rapid incident response, pinpointing the root cause
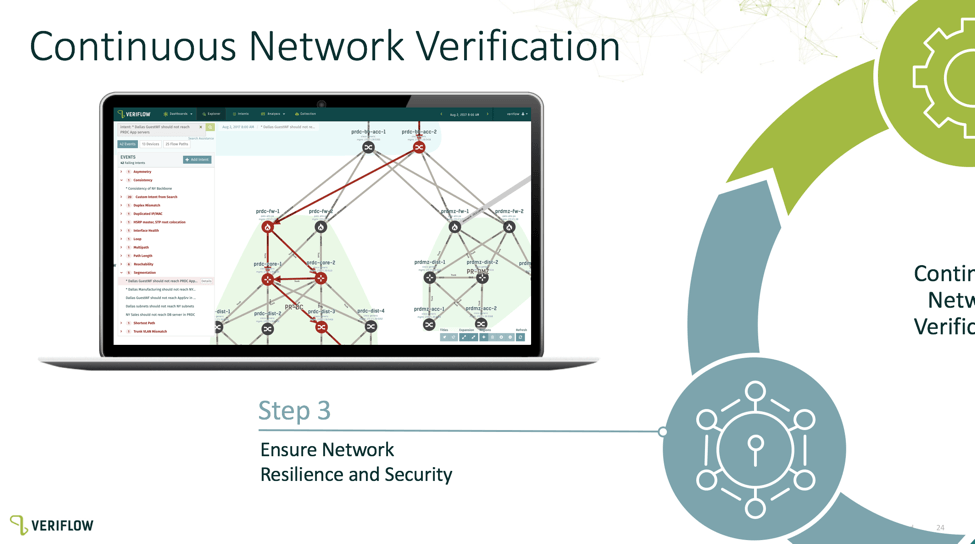
Recently, we are hearing a lot about “Intent-Based Networking.” Veriflow has something to say about that (see their Resources page). Their product does verification that the design/implementation (operations) complies with business intent, in vendor-agnostic ways.
The challenge with “intent-based” is how you convey the intent. This was a key question for #NFD16 delegates — several of us realized that the tools helped automated checking of policy, but that to a degree just moves the labor to defining the policy.
One thing Veriflow does is makes it easy to convert items you test to intent rules. This can be specific A-to-B type connectivity (or segmentation), or it could be much broader (tags, groups of devices, etc.).
Veriflow not only collects configuration information to model the network with, but data plane forwarding and Cisco show command output, to include the current state of the network, with time stamping and snapshot capability.
They’ve also built out a long initial list of “auto-intent” items — and it’s possible more might be coming. The sort of thing Veriflow can check: if HSRP is configured, is there a properly configured peer. One example of a challenge with this: maybe you configured HSRP but have yet to deploy router #2. So either take active state into account, or tag “pre-deployment” items.
Veriflow calls this feature “Intent Inference.” It is Spanning Tree and ECMP-aware, so it can do things like catch failover situations where one ECMP alternative will not pass the required traffic (or fails to block disallowed traffic, in a segmentation validation scenario).
This sort of low-level checking is exactly what humans miss. When I do network assessments, lately I’ve been finding a lot of “network entropy,” as in drift or randomness in configurations, resulting in things like trunk allow mismatches, HSRP peer not configured, misconfigured, or just not present for some reason, and many other such things. Design issues tend to be more interesting for all concerned, but it’s that low-level stuff that can really create a lot of hidden problems that will at some point consume your troubleshooting time. Or worse, defeat failover when there is a failure in the network. If we can automate them away, that saves real time for us! For big companies (airlines, online commerce, financials), it potentially saves on embarrassing service outages.
As evidence of the importance of this, I’ve seen two large enterprises do an HA validation, one at the config level (is HSRP or VRRP configured, does the static route to the firewall have the VIP as the next hop, etc.), and the other at the config plausibility level, followed by failover/fallback testing during a weekend change window. Times 900 points of HA. That took a team of several engineers a year to complete using weekend change windows. The cost of doing that might have paid for a Veriflow license several times over!
That sounds like a cost ROI case for having something like Veriflow doing “continuous verification.” It may not be 100 percent perfect the way actual testing failover is, but if it greatly improves the odds that HA will work as intended, or that other things will work as intended, that’s a big win. Catching other sorts of configuration errors (device IP not in right subnet, duplicate IP, mismatched subnet masks, etc., etc.) could be equally important.
The same applies to operations and rapid response. Having a tool spot the path traffic is taking and which ACL rule is blocking it saves time and lowers cost because the Tier 1 and 2 staff can solve more problems.
I recall a long day into evening session with the “brain trust” in a room for quite a while, trying to figure out why there were alerts that the major e-commerce web service was down when outside verification showed it as up. It turned out the internal monitoring tool’s routing was wrong, going inside rather than outside to get to the website, and being blocked. After we caught onto that (with a little help from ThousandEyes doing external monitoring), we spent hours figuring out the path, where it was blocked, how to fix the routing, and getting two firewalls’ static routing and NAT points sorted out.
Veriflow flow checking would likely have rapidly identified the problem, and better, allowed us to test the proposed solution before deploying it. Further, if it had configuration and routing snapshots, we likely could have pinpointed what change triggered the problem in the first place.
The offline troubleshooting aspect of this sort of tool really gets my attention. I’ve seen multiple people tied up for hours trying to solve a problem, which turns out to either be routing or an access list (or the two working against each other). Normally we have to do traceroute to and from the target, then check each hop for routing, ACLs, and other factors. Veriflow speeds that up a lot!
All that of course assumes the model is faithful to the actual network behavior. Veriflow has some sharp people working for it. Having said that, could there be special undocumented, “interesting,” or odd modes of Cisco IOS or NXOS behavior? Darn sure, and I’ve got the scars to prove it! Try redistributing OSPF on a Cisco device with OSPF area 1 configured and no area 0, for example. Does Veriflow catch all such? Maybe a lot of them; probably not all.
Veriflow also has an API, which apparently is quite powerful, letting you automate creation of intent rules. Using the API, you can also query the Veriflow database and correlate the data in ways the product doesn’t already do. The example online (see the API link above) shows code to check for MTU mismatches. I’ve been fiddling around with some Python configuration checking just using captured configurations. Extracting knowledge of neighbors on a link and their state is hard to do without something like the network device and topology models inside Veriflow. Having access to all that lets you extend the capabilities of the tool in powerful ways, without having to wait for the developers to code them up. Leveraging Veriflow could also save you the work of building a topology model from configuration files and/or the live network, allowing you to get what you need faster.
This is something I don’t hear in “networking people should code” discussions: the best use of your time may be supplementing existing tools, not building tools from scratch. YMMV.
Other features discussed:
- Pre-Flight checks: use the model to verify changes before deploying them
- Cloud Predict, with AWS visibility
In summary, Veriflow is doing a lot of interesting and exciting things, and doing them fast. To learn more, check out their website. But first, check out the #NFD16 recorded video of the Veriflow presentations and demos.
Links
- Blog: NFD16 Day One – Veriflow
- Blog: Veriflow – The Formal Future
- Blog: Startup Veriflow Adds New Intent-Based Capabilities to Its Network Verification Software
Comments
Comments are welcome, both in agreement or constructive disagreement about the above. I enjoy hearing from readers and carrying on deeper discussion via comments. Thanks in advance!

