
In A Network Management Architecture, Part 1, I discussed a Network Management Architecture, composed of seven elements, shown in the figure below. I described the Event and NCCM elements in that post.
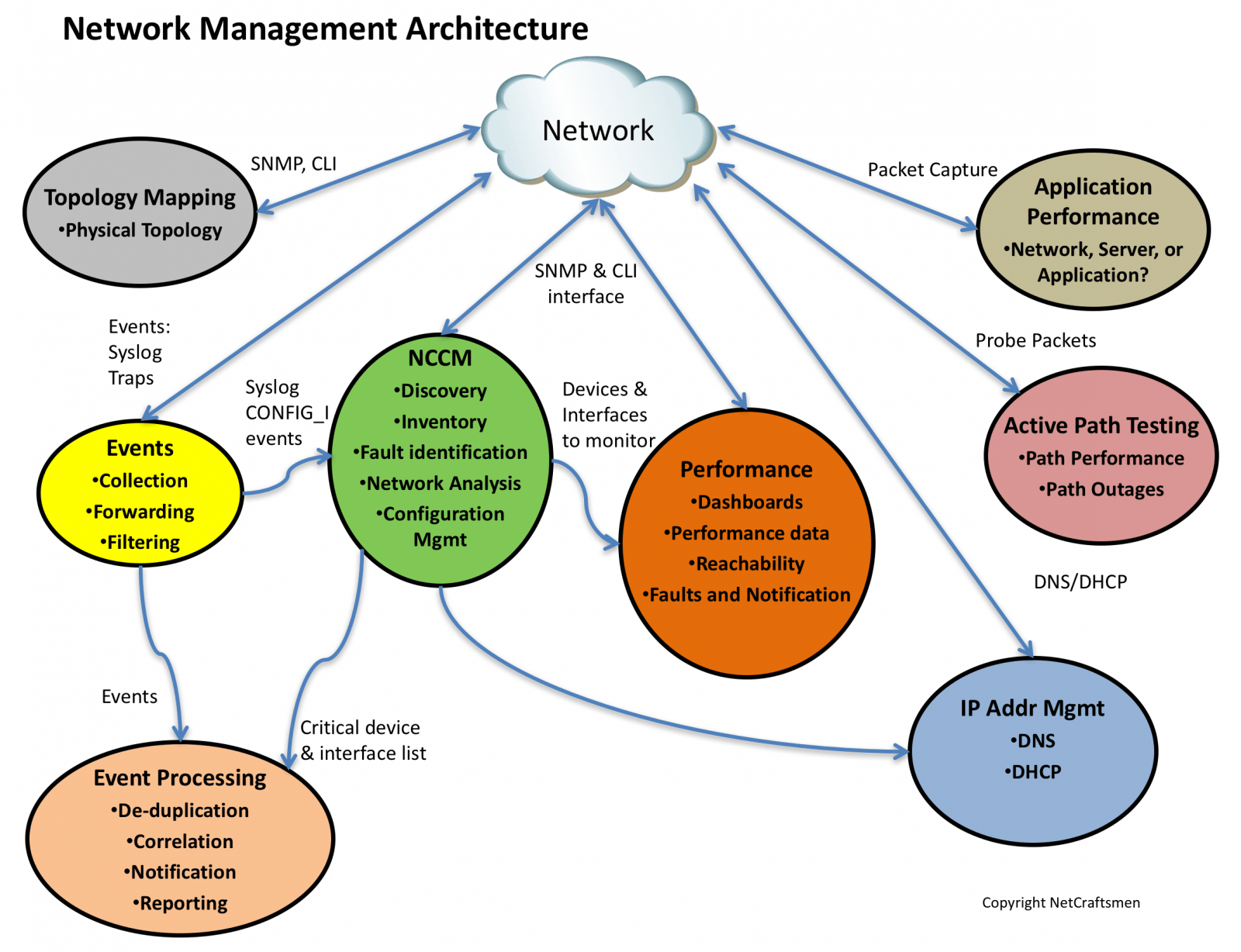
Performance monitoring is typically where most people focus their early network management efforts. I think that’s because it is easy for an organization’s management to understand and it is relatively easy to implement. A lot of tools provide performance monitoring, with the Top N displays of utilization and errors being the most popular views.
With a few exceptions, interface utilization monitoring in modern networks isn’t very useful. Most networks today have very high speed links and the typical 5-minute utilization is relatively low. However, burst utilization may be high, but the monitoring tools typically can’t poll all interfaces at rates that provide visibility into bursts. Instead, take a look at the infrastructure and determine which links are critical aggregation points and configure the performance monitor to poll for utilization data on these interfaces at much faster rates, possibly as fast as every 30 seconds. If you have a link that you suspect is having problems, polling every 10 seconds may show burst congestion. (Note: MIB variables are updated relatively slowly. I’ve heard 3 seconds before, but found two articles that suggest that the update period is 10 seconds:
I find that interface error monitoring is the most useful part of performance monitoring. A duplex mismatch looks like a high error interface because most tools count collisions on half-duplex interfaces as errors. There are several key error types that indicate a duplex mismatch: any late collisions on a half-duplex interface; FCS, CRC, and Runts on a full-duplex interface. I’ve seen interfaces that have logged more than 1,000,000 packet errors per day. These are very likely very busy servers with a duplex mismatch. The packet loss would result in very low network performance. (See my post on TCP Performance and the Mathis Equation .)
Of course, it would help to have the performance monitoring system configured to generate alerts when error thresholds are exceeded. I prefer to use very low error thresholds because modern network links should run with very few errors. In one instance, a fiber link was experiencing about 100 errors per day while all the other fiber links in the same infrastructure were running clean. While 100 errors didn’t affect the link’s throughput, it indicated that something was different about the link. The solution was to replace the fiber jumpers on the ends of the link. Of course, there are exceptions, such as microwave links and noisy environments like those found in military tactical networks. Examine these links and pick reasonable error thresholds for them, based on what they normally experience.
IP Address Management
Most people probably don’t associate IP Address Management with network management. I think it is a key component, because of the number of problems we’ve seen in network assessments where there are duplicate subnets or inconsistent subnet masks, or where the address management function is performed using spreadsheets and other non-scalable mechanisms. (Tip: If you insist on using a spreadsheet, put the data into a Google Docs spreadsheet. It will allow you to see who else is modifying it, eliminating one of the most common problems: who has the current copy and how you synchronize changes.)
I recently created a migration plan for a customer who needed to readdress a significant piece of their network. All the printers were statically addressed. Changing the addresses on them on the cutover day wasn’t going to be fun. But I did some homework and found that the printers were typically only access from a set of print servers. The print servers could use printer names from DNS. So the solution was to add the printers to DNS, and change the print servers to use the DNS names. Then the printers could be assigned their current static address in DHCP. The field team then changed the printers to use DHCP, but did this job over the course of several weeks. Now the address assignments for printers was centrally controlled. It made the migration easy: set DHCP and DNS timers to low values (30 minutes), update DHCP with the new addresses, then wait for the printers to get their new addresses. When a new address was acquired, Dynamic DNS was updated and the print servers could access the printer at the new address.
The other important use of IPAM is to know where devices are located in the network. There is an initiative called IF-MAP (Interface for Metadata Access Points) that is used to track network endpoints. This is where you go when the security team comes up with an IP address of a workstation that is a security threat. Where is it located in the infrastructure? What switch port needs to be disabled to take the workstation off the network?
I’ll continue the architecture review in the next post.
-Terry
Other posts in this series:
NetCraftsmen would like to acknowledge Infoblox for their permission to re-post this article which originally appeared in the Applied Infrastructure blog under http://www.infoblox.com/en/communities/blogs.html.