
This is the 10th blog in an Internet Edge series.
Links to prior blogs in the series:
- Internet Edge:Simple Sites
- Internet Edge:Fitting in SD-WAN
- Internet Edge:Things to Not Do (Part 1)
- Internet Edge: Things to Not Do (Part 2)
- Internet Edge: Two Data Centers
- Internet Edge: Double Don’t Do This
- Internet Edge: Cloudy Internet Edge
- Internet Edge: Special Cases and Maintainability
- Internet Edge: Security Tool Insertion
This is the first of three blogs on the topic of Internet Edge traffic steering.
I am avoiding the term “traffic engineering” since engineering sounds precise. “Precision” is a word rarely used in conjunction with “Internet.” Let alone Internet traffic routing intent.
Instead, this blog is about how your Internet Edge routers might exert some control over which way selected inbound and outbound Internet traffic goes.
 Starting Assumptions
Starting Assumptions
Assumptions:
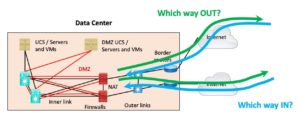
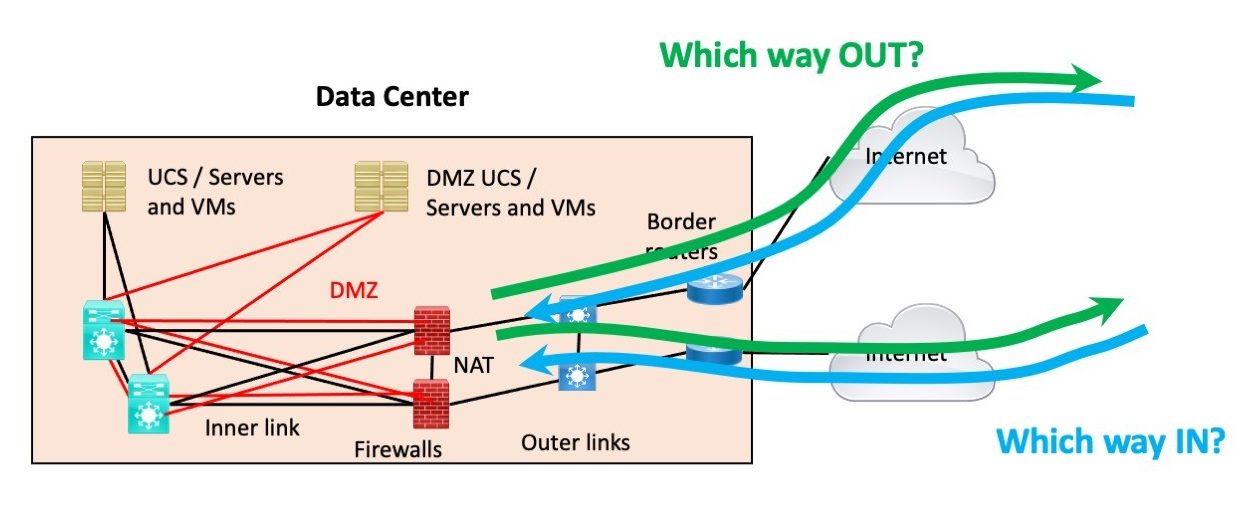
- You have two or more Internet links, either on one router or on two routers (1 each)
- If two sites are involved, you have the “outside the firewall crosslink” described in an earlier blog in this series (to make IBGP feasible and to keep things a lot simpler).
- If you do not have the outer crosslink, any asymmetric paths will lead to firewall traversals and a rather complicated situation. That generally ties inbound to outbound traffic steering and leverages NAT to force symmetric paths.
- You have a good reason to want to do traffic steering (or need more complexity since your life or your network is boring).
Reminder: in an earlier blog in this series, I advised against receiving a partial or full Internet table unless you have a good reason to. Traffic steering is one case where there might be a good reason to receive a partial feed, perhaps some or all prefixes from a given ISP (likely filtered inbound by AS number(s), if you want the ability to select parts of a full feed).
“One hop prefixes,” i.e. those originated by the ISP, are one common partial feed. You can then choose which to allow in, and which to ignore, if you want finer tuning.
Why Do Traffic Steering?
Apropos of “you think you have a good reason to do traffic steering,” – let’s talk about that. There are good reasons and bad reasons. You’ll notice my list below says “managers” frequently.
Let’s consider good reasons first. The most typical is that you have two (2) or more Internet links; one is fairly heavily used, the other(s) not used or lightly used unless the first one fails. “Fixing” that might be a good idea, or not. We’ll come back to this topic below. Another good reason is your organization offers some service, e.g. banking, and you want low latency and more robust connectivity to your customers. In that case, you might want to steer customer traffic to “eyeball ISPs” (those serving home/business users) rather than Tier 1 backbone providers. Using Tier 1 provider, the responses might transit more inter-ISP transit links, which could be congested. Going direct to the eyeball ISPs has less transit hops, plus there is less BGP in between to create routing instability or delayed convergence.
Another good reason is your organization offers some service, e.g. banking, and you want low latency and more robust connectivity to your customers. In that case, you might want to steer customer traffic to “eyeball ISPs” (those serving home/business users) rather than Tier 1 backbone providers. Using Tier 1 provider, the responses might transit more inter-ISP transit links, which could be congested. Going direct to the eyeball ISPs has less transit hops, plus there is less BGP in between to create routing instability or delayed convergence.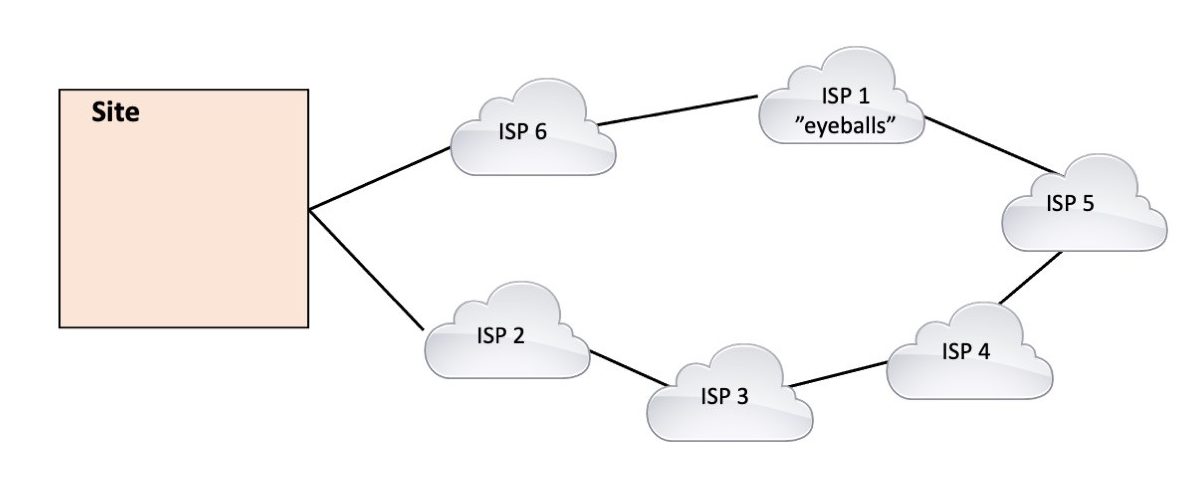 Then we get to the less good reasons … This is where I sometimes feel I’ve provided more consulting value, talking people out of doing traffic steering or working through alternatives to end up with something much simpler that does what is really needed.
Then we get to the less good reasons … This is where I sometimes feel I’ve provided more consulting value, talking people out of doing traffic steering or working through alternatives to end up with something much simpler that does what is really needed.
Best words ever: “What problem are you trying to solve?”
(Of course, to be followed up on by asking about constraints.)
Case 1
One consideration is managers and the number of Internet links. I’ve been at several sites where there were two Internet links, and as soon as congestion or some issue occurred, the manager wanted more links.
Here’s the picture: one big link per site, or two links of half as much bandwidth, per site.
 Getting more links may increase your Internet robustness, assuming the new links don’t share fate (path or common equipment) with the existing links. Having different providers may help with diversity or not – they may be leasing fiber from a company that owns all the fiber into your neighborhood or building.
Getting more links may increase your Internet robustness, assuming the new links don’t share fate (path or common equipment) with the existing links. Having different providers may help with diversity or not – they may be leasing fiber from a company that owns all the fiber into your neighborhood or building.
On the other hand, you will have to use those links, which may or may not take some extra effort. Otherwise, the question “why do we have this <provider> link if we’re not using it?” will inevitably arise.
For outbound traffic, ECMP (Equal Cost Multi-Path) routing of the default 0/0 route may split the traffic roughly equally. Ok, that’s low effort to implement.
For inbound traffic, unless there are two links to one ISP where ECMP applies from the ISP’s perspective, you may need some traffic steering to get to better (but still very approximate) equal loading inbound.
Looked at from a different perspective, putting twice the bandwidth in one link saves you from possibly having to create and manage the configuration to balance traffic across two links and having to monitor/tune the utilization.
This comes back to “what problem are we trying to solve”:
- Adding more bandwidth
- Increasing robustness (usually why 4 links looks better than 2 to someone)
Personally, I suspect going from 2 to 3 or 4 Internet links maybe moves you from 99.9% uptime to maybe 99.99% at best, IF your other operational practices are optimal. The competing factor is adding complexity is likely to increase downtime (decrease robustness).
It can be important to set expectations around ECMP. Traffic will be shared across the parallel routing paths. Traffic levels will, at best approximately equal. And that is “crudely approximately equal” or “very roughly approximately equal.”
Case 2
A second manager-related topic is utilization. If you have two or more links, some managers may want all the links used, or even roughly equal use of all the links.
This does have the advantage of making sure the links actually work (assuming 2-way traffic).
This is subject to what I wrote above re complexity and management time costs. If there’s something simple, that evens up the utilization load somewhat, fine, little harm done. Doing heavy traffic steering to achieve approximately equal use of the links: may take a good bit of effort, trial-and-error and may need ongoing management and tuning. The ROI on the time that takes is likely low. (Versus the value of making your manager happy?)
Case 3
A third manager-related topic is utilization.
“Why are we only running at 10-20% utilization? We could save money!”
Unless you have a flexible ISP contract, you are probably capped by either the circuit speed (1 vs. 10 Gbps commonly now) or by the burst speed (if you have a burstable circuit, say 2 Gbps on a 10 Gbps circuit, with high costs for sustained exceeding the burst level).
In either of these cases, you are likely on a multi-year contract. If you run out of bandwidth, you’ll be dropping packets. And changes may trigger a penalty payment plus consume time. In the second of these cases, there may be fees associated with changing your bursting level, assuming that is even permitted.
In short, I suspect most Internet circuit contracts leave you stuck with an inflexible amount of bandwidth that is hard to change and takes time to change. (I say “I suspect” since I have never actually had the dubious pleasure of reading such a contract. Life goal achieved!)
With burstable contracts, it is almost inevitable the topic of QoS will come up, as in “can we apply some QoS, so we don’t get surprised by these big bills?” The answer is yes, but you’ll have to configure the traffic shaping or policing. That’s a hidden cost of burstable contracts!
In either case, there is a trade-off. Unused bandwidth costing real money. Versus scarce staff time managing traffic steering and link utilization.
Worse than that, using and paying for “no more bandwidth than we need” can create work and also make things worse (slowness) if pushed too far.
The Cost of High Utilization
Here I wish to note (rant?) that it may be unwise to run a circuit at more than say 70-80% capacity. That is because any short-lived bursts mean you’ll be dropping enough packets to significantly slow down data transfers due to retransmissions. (See also “Mathis’ Formula”).
Not to mention queuing delay – waiting for the previously sent packets in the queue to actually be sent.
A rough approximation is that with utilization percent u you will have q = u / (1-u) packets queued up on average. At 90% utilization that works out to .9 / (1 – .9) = 9 packets queued, on average. At 95%, .95 / (1 – .95) = .95 / .05 = 19 packets. Definitely increasing latency!
To sum up: unused bandwidth or “headroom” is good because it buys you time until you have to get a faster circuit, and it reduces the queuing delay and the number of dropped packets and retransmissions, resulting in moving traffic faster.
There is yet another advantage to headroom. Let’s call it “Stuff Happens.” That is, there will be events that cause higher levels of traffic. The ultimate cause is “humans.” Some of the ones I’ve seen or heard of recently:
- OS, VPN, or application updates are being pushed to WFH users. That may crush the VPN capacity of the router or firewall before it crushes the Internet link.
- Outside penetration/security verification, e.g., outside attempts to connect to a range of IP addresses and TCP ports. That can manifest as a traffic problem or the sheer number of flows/second impacting the CPU on the router or firewall, etc.
- Transferring a lot of organization data (copy or backup) to AWS S3, causing congestion for others and perhaps taking too long to meet deadlines for the data move/copy operation.
Also worth noting: inbound and outbound traffic levels are generally rather disparate. One direction often has much less traffic than the other. You may be able to “pay for what you need,” but then you would have to monitor two traffic levels, i.e., have more complexity. Are the savings (if any) worth it?

