
This is the 11th blog in an Internet Edge series.
Links to prior blogs in the series:
- Internet Edge:Simple Sites
- Internet Edge:Fitting in SD-WAN
- Internet Edge:Things to Not Do (Part 1)
- Internet Edge: Things to Not Do (Part 2)
- Internet Edge: Two Data Centers
- Internet Edge: Double Don’t Do This
- Internet Edge: Cloudy Internet Edge
- Internet Edge: Special Cases and Maintainability
- Internet Edge: Security Tool Insertion
- Internet Edge: Internet Edge: Traffic Steering Part 1
- Internet Edge: Internet Edge: Traffic Steering Part 2
This is the third blog of three on the topic of Internet Edge traffic steering.
Outbound Topics
I consider filtering / not filtering prefixes to be the simplest outbound technique.
Simplest form: Accept default from both ISPs, and allow selected other prefixes in from the ISP with the less-loaded outbound link to shift traffic to it. I generally would do that after pre-filtering to at most accept only prefixes with 0 or 1 ASN in the AS-PATH. Even that will probably get you many prefixes to work with!
Fancier form: Accept default from both, and allow selected prefixes in from each ISP. It is probably best to allow in one hop prefixes (obviously, the ASN will then be just the associated ISP). This has the benefit of sending traffic directly to customers of each ISP by the shortest path.
If your Internet Edge design has an outer link (between data centers when considering two data centers), then you can run iBGP across it. You can then set BGP weight (single router over-ride, basically), local preference (shared indicators of which is the preferred exit), or MED (but why use it).
Note: Weight or local preference can be useful when you have a single router talking BGP to two ISPs (or in other BGP settings). I tend to think of them more in conjunction with iBGP and two routers, for some reason.
If you run iBGP across more routers, things start getting complex. You can use route reflectors if you have many Internet-connected peers. Most will have at most 2-4 such, where route reflectors can help but not much.
The bigger thing that I’ve seen as a potential issue is not having an iBGP full mesh (including links, not just BGP peering’s). This applies to use of route reflectors as well.
You can then set BGP policy all you want, but unless the IGP matches, it won’t always work. (When the BGP next-hop has the “wrong” IGP next hop). I personally tend towards iBGP with set next-hop-self in full meshes, even if that might be overkill. It doesn’t break in obscure ways.
What I see a lot more lately is internal EBGP because of BGP for MPLS WAN, BGP for CSP connections, and BGP for Internet. And BGP between data centers.
If you designed as suggested in an earlier blog, you might be able to use the data center core routers as iBGP route reflectors in each site, also reflecting to each other. Any more route reflection can get ugly fast. I’m thinking of tiers of route reflectors or site core routers route reflecting their reflection clients to each other. Don’t design that way!
Recently, however, I’ve seen many sites with more complex internal structures, with or without an outside link. In such sites, EBGP is preferred, so each BGP hop will pass along prefixes without having to create a mess of route reflectors due to the complex or awkward connectivity. (This is also a sign of, “it happened over time without a grand plan.”)
EBGP does provide good hints about how a given router learned a prefix.
One drawback is that EBGP then “eats the core of your network.” We used to see that with OSPF area 0 expanding over time. Well, over the past few years, BGP has been taking over!
The following diagram shows the use of routing protocols I’d be most comfortable with, assuming EBGP is “consuming your Internet Edge.” (Not showing any IGP.) If there is an outer cross-connect, then I’d add iBGP between the border routers, on the right side of the following diagram.
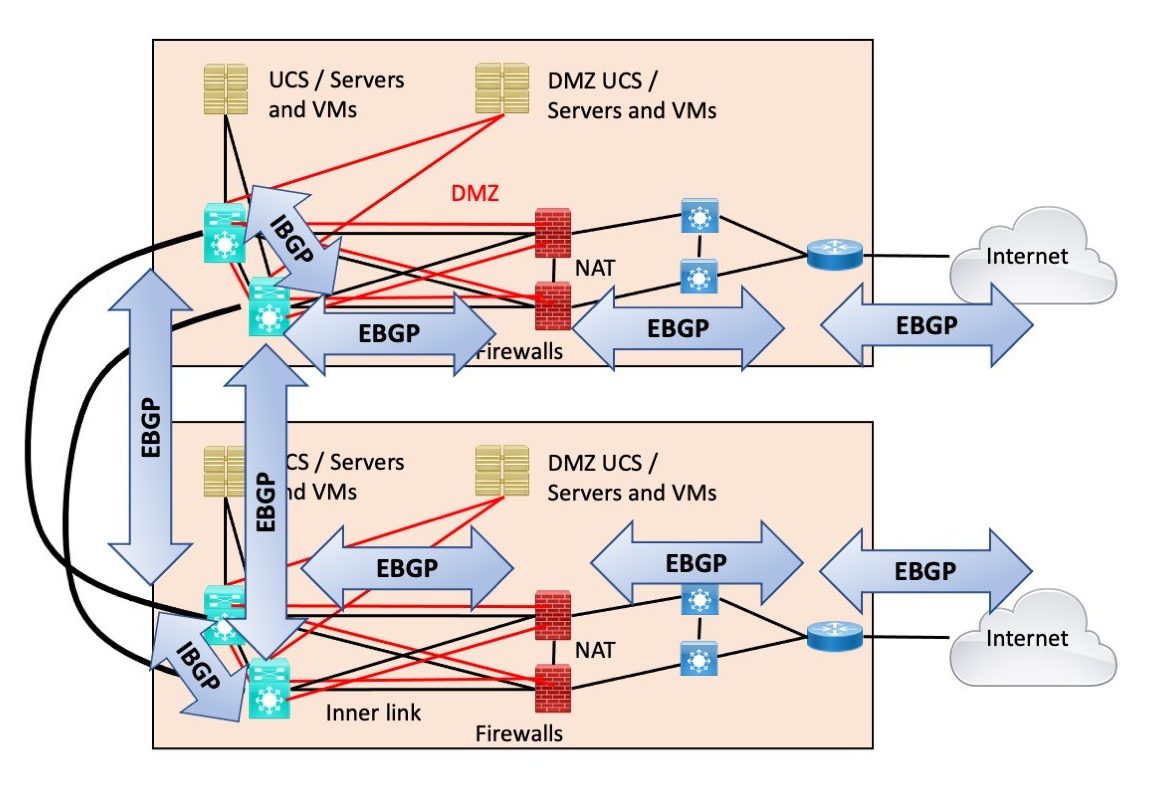 The issue here is that redistributing BGP into an IGP doesn’t really give good policy control, especially if your IGP is OSPF.
The issue here is that redistributing BGP into an IGP doesn’t really give good policy control, especially if your IGP is OSPF.
The consequence of this design is BGP taking over the data center/core of your network. Is that a Good Thing?
Case Study: Bank and Customers
I alluded earlier to customer-aware routing. That actually happened to a colleague who once worked for a large bank. They wanted to improve customer experience; I gather perhaps more due to routing instability in routing via the Tier 1 ISPs towards their customers. They put in circuits to Xfinity / Comcast and a couple of other providers “with many eyeballs,” accepted the relevant prefixes, and routed directly to those customers. The end result was deemed well worth the effort.
Case Study: Running Out of Bandwidth
An organization I worked with was running out of bandwidth on 1 Gbps ISP links while waiting for the installation of its new 10 Gbps Internet links.
The outbound traffic was the problem, consisting of replies to web queries, etc. COVID staff WFH.
The less-used circuits outbound were from AT&T. The customer added batches of tens of AT&T customer prefixes to be allowed in from AT&T. On the other ISP, just default. The more specific AT&T prefixes would send any traffic to one of the matched AT&T destinations out via AT&T.
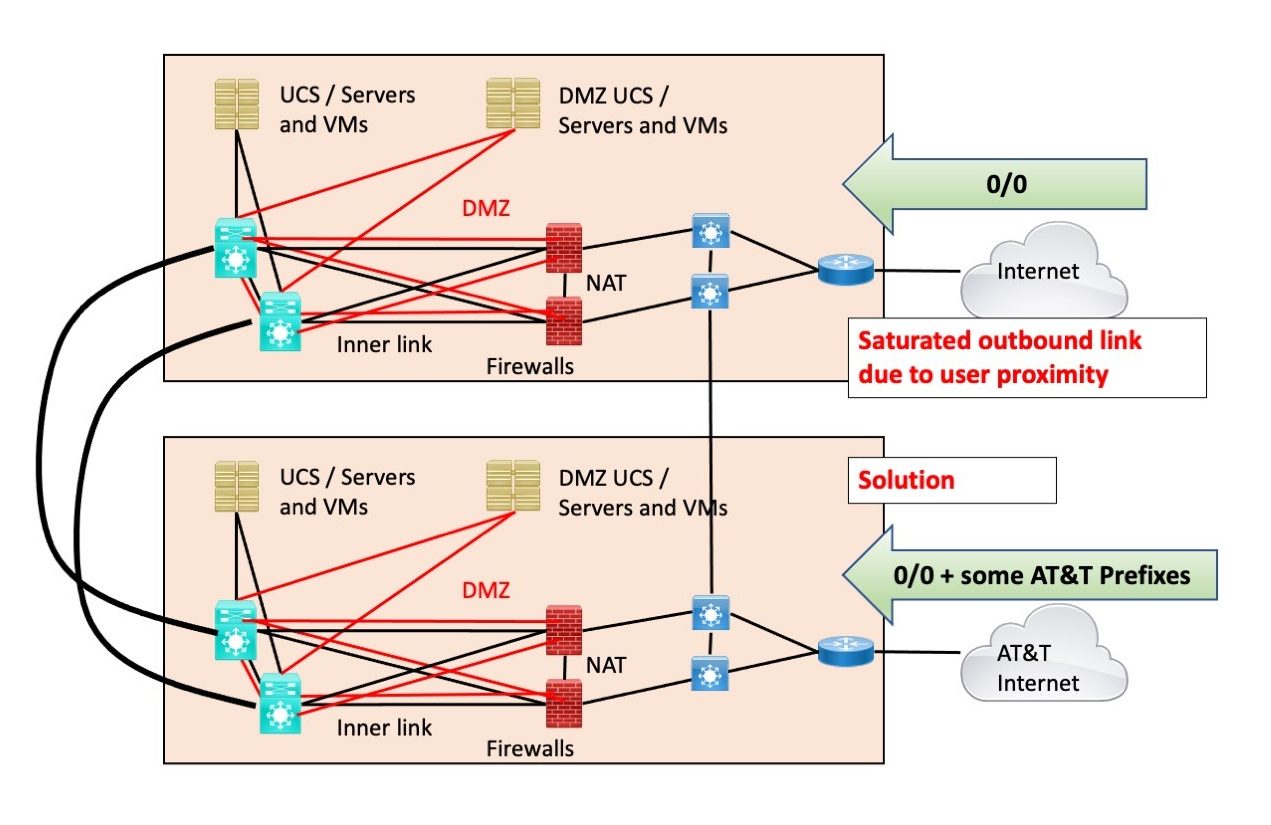 The customer then watched the traffic levels as replies going to AT&T customers shifted over to the AT&T links. I gather 100-200 prefixes sufficed to roughly balance the traffic out.
The customer then watched the traffic levels as replies going to AT&T customers shifted over to the AT&T links. I gather 100-200 prefixes sufficed to roughly balance the traffic out.
I’ll note that it might have been simpler to just accept all prefixes associated with an AT&T AS number. But that might have swung too much traffic over!
In general, I liked the customer’s approach on this: ok, let’s try something gentle, see the effect, and if we like it, do some more of it, but nothing drastic. In this case, this meant looking up AT&T’s AS numbers, checking for prefixes (looking glass or allowing them in), then picking some and filtering further. Probably after hours.
Case Study: Random Outbound
Something I saw in the field… A fairly small organization had two routers, two Internet links at HQ / datacenter. If I recall correctly, the two routers accepted full feeds, which struck me as overkill. Anyway, they ran iBGP and were set up with local preference rules. Traffic to customers with addresses with odd third octets went one way, evens the other.
The person who set that up said he thought that was the best way to achieve a fairly even random distribution. I didn’t disagree. I definitely thought “CCIE over-thinking it.”
Sometime later, we changed that site to accepting only default route, passing 0/0 to the firewall(s), and ECMP routing on the firewall. Much simpler!
Case Study: Moving Data to AWS S3
Very recently, an organization with a lot of data for public consumption was copying or updating a lot of data to AWS S3. It was taking too long to meet the initial deadline. Also, periodic and/or continuous updates would be a recurring operation. Outbound while populating AWS, then inbound replication when the primary copy of the data became the AWS one.
We discussed alternatives. I did some Python scripting around DNS queries and accumulating responses since AWS was apparently DNS load-balancing the front end for the inbound S3 storage service. I’ll spare some details here.
The idea we had was that we might hard-code the IP in the URL on the sending side and have the chosen Internet path advertise that /32 prefix inwards in the IGP (EIGRP). We could then use some small number of /32 advertisements to “deflect” the traffic, assuming that didn’t create problems with AWS somehow.
It turns out AWS publishes a list of IP blocks by region and service in JSON format. Picking up the relevant prefixes from that list (region + S3 service) and advertising them inwards in the IGP is a cleaner approach.
What seemed attractive about a /32 was testing with little / no potential to have ill side effects on anything but perhaps one of the flows for the AWS S3 uploads. The worst-case seemed like it might have been if AWS was spinning up front-end instances on the fly or that the front-end instance might fail/be killed off and not be replaced at the same IP address.
The network team and the group owning the data and application front end talked to AWS to get their recommendations. The end result was contracting for a dedicated link.
I’ll note that this cleverly moved the financial responsibility to the application group, which is where it belonged. That’s at the Organization Politics level of the OSI model, by the way. There is still the issue of routing to use the new link(s). But private addressing for AWS S3 endpoint(s) in the terminating VPC should be one clean way to solve that.
This was a non-technical consideration, which is why I’ve included this story. Somebody’s got to pay for bandwidth, and if there’s to be a long-term consumer of a lot of bandwidth, budget/finances is definitely a very real consideration. (“Financial Engineering”?)
Advanced TE
I blogged about a corporate internal BGP traffic steering situation previously. If you’re building a high-speed dual backbone between CoLo or Cloud locations, or data centers, this might be of interest. The point was to find a simple but moderately granular way to control traffic across parallel high-speed backbones.
The idea we ended up with leverages a mix of iBGP and EBGP to create “rails,” i.e., routing where traffic sent out one side tends to stay on that side of the two, the A or the B side. The point is that choosing which “side” to send traffic out along concentrates the logic at the edge routers for each site.
I’ve seen something similar done with OSPF by putting a higher cost on the crosslink between the two core switches at each site or tier along the “railroad track” (lineup of cross-connected switch pairs).
Conclusion
When you get right down to it, at an organization that is not an ISP or WAN provider, there is a fairly limited set of “traffic steering” tools you can use with BGP.
Assuming you have an outer link between data centers, or are doing NAT, you can, to some extent, steer traffic inbound and outbound. With no outer link, NAT causes inbound and outbound to be coupled to each other: less flexibility regarding traffic steering.
My sense is that the more specific prefix approach is a clean, simple, and reliable way to steer traffic.
For inbound traffic, assuming you have enough /24 or larger prefixes to advertise outbound, AS-PATH prepending is simple and commonly used. If your ISP (singular) supports using BGP communities to indicate your policy preferences to them, that is a good alternative.
I hope this discussion has been useful, and I wish you success with Internet traffic steering!
More Reading
It turns out Russ White was publishing some relevant blogs as I was writing this. You can dig a little deeper into AS-PATH prepending by reading them:
- https://rule11.tech/the-effectiveness-of-as-path-prepending-1/
- https://rule11.tech/prepend-fails-next-2/
- https://rule11.tech/prepend-fails-next-3/

