
This blog attempts to cover some of the things you might want to consider when designing an SD-Access deployment for more than one site.
Previous blogs in this series:
- What Is SD-Access and Why Do I Care?
- Navigating Around SD-Access
- Managing SD-Access Segmentation
- Securing SD-Access Traffic
- SD-Access Single-Site Design
So what‘s the big deal? We covered how to plan and design a single site (at a high level, at least). The rest is details: which VN‘s, which SG‘s, what IP pools, floor plans for wireless heat maps, etc.
Well, yes and no. When you have several or many sites, everything becomes bigger and more critical. Planning is part of providing robustness. There is also large deployment planning, but that is a separate topic.
My claim is that you can certainly proceed site-by-site and probably succeed. My preference is to organize a bit upfront, also plan the big picture. You can get by without that. But doing it, upfront may be helpful. Figuring it out on the fly can easily leave you with inconsistencies.
Multi-Site Topology Review
In case you were expecting more details of multi-site, well, it’s a bunch of sites. We know what sites look like at this point. They’re connected by either global core routing, VRF’s across the core, or SD-Access Transit VXLAN tunnels. The Securing SD-Access Traffic blog covered that.
The following diagrams are intended to pull the previous material together for you, summarizing the topology. The diagrams suggest the cabling / connectivity but have been simplified to reduce clutter. (I have to admit, drawing lots of “bowtie” connections isn’t appealing at the time I am writing this.)
And yes, your datacenter topology probably isn’t quite like what I drew. The key word here is “simplified”. You probably have at least two datacenters – but I only need to show one to convey the concept.
The first diagram below shows the generic setup. I’m ignoring sites with their own direct internet access here.
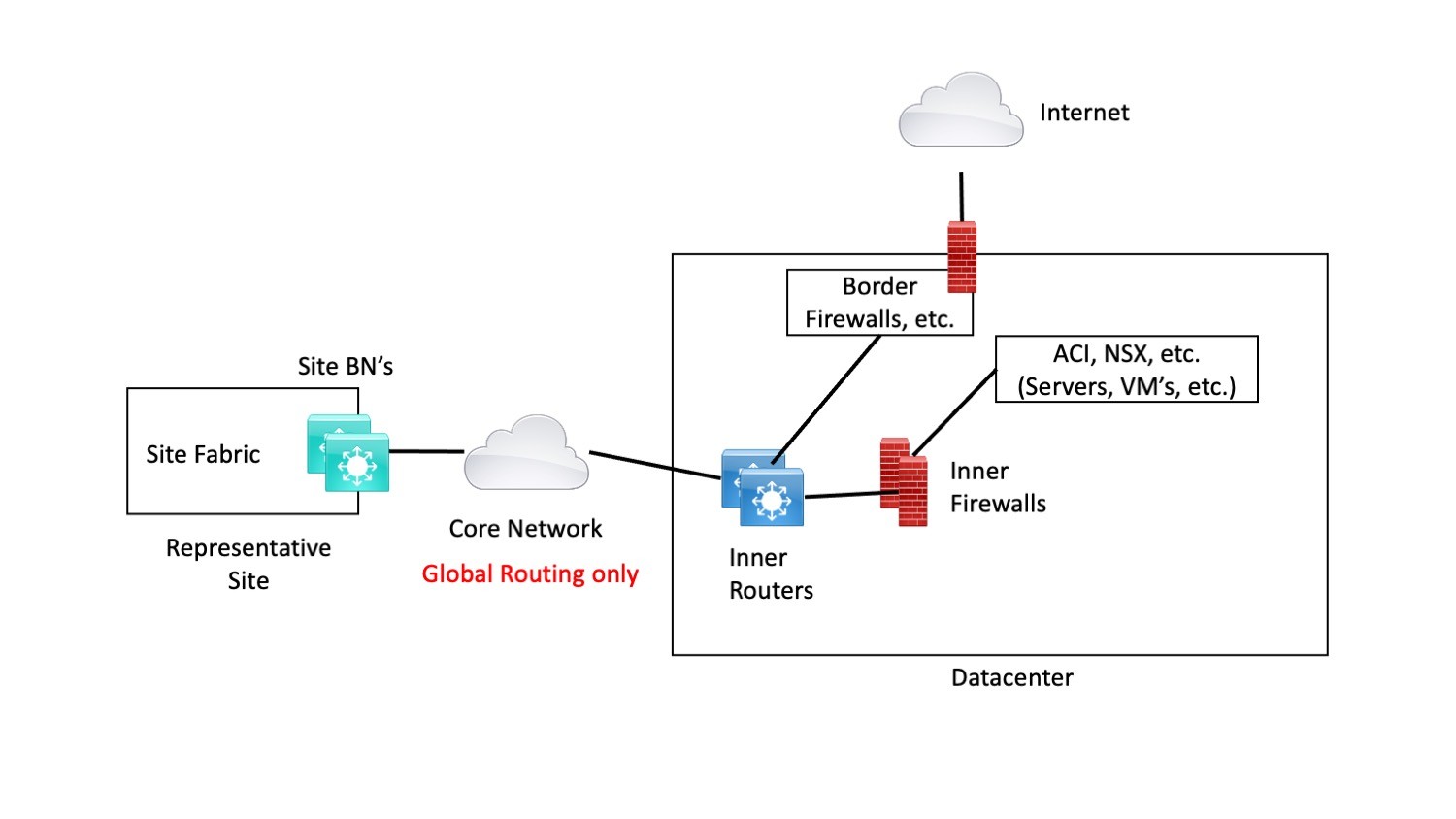
This is the basic IP Transit model. The Core Network has global routing only, so segmentation is not maintained between sites or from sites to datacenter. On the other hand, pxGrid or SXP can be leveraged on any firewalls in the path from users to servers, or used by ACI.
As we saw previously, the next major approach is doing VRF’s across the core. That takes a good bit of work to set up, but is arguably a bit simpler. The following diagram attempts to show that stitched together with the prior fusion firewall diagram.

With this approach, the core VRF’s interconnect sites, preserving segmentation. They also extend to the fusion firewalls, which merge and filter the traffic, exiting in the global routing table to get to the rest of the datacenter. The fusion firewalls have SXP and pxGrid available, to map user IP’s to SG’s for SGACL enforcement.
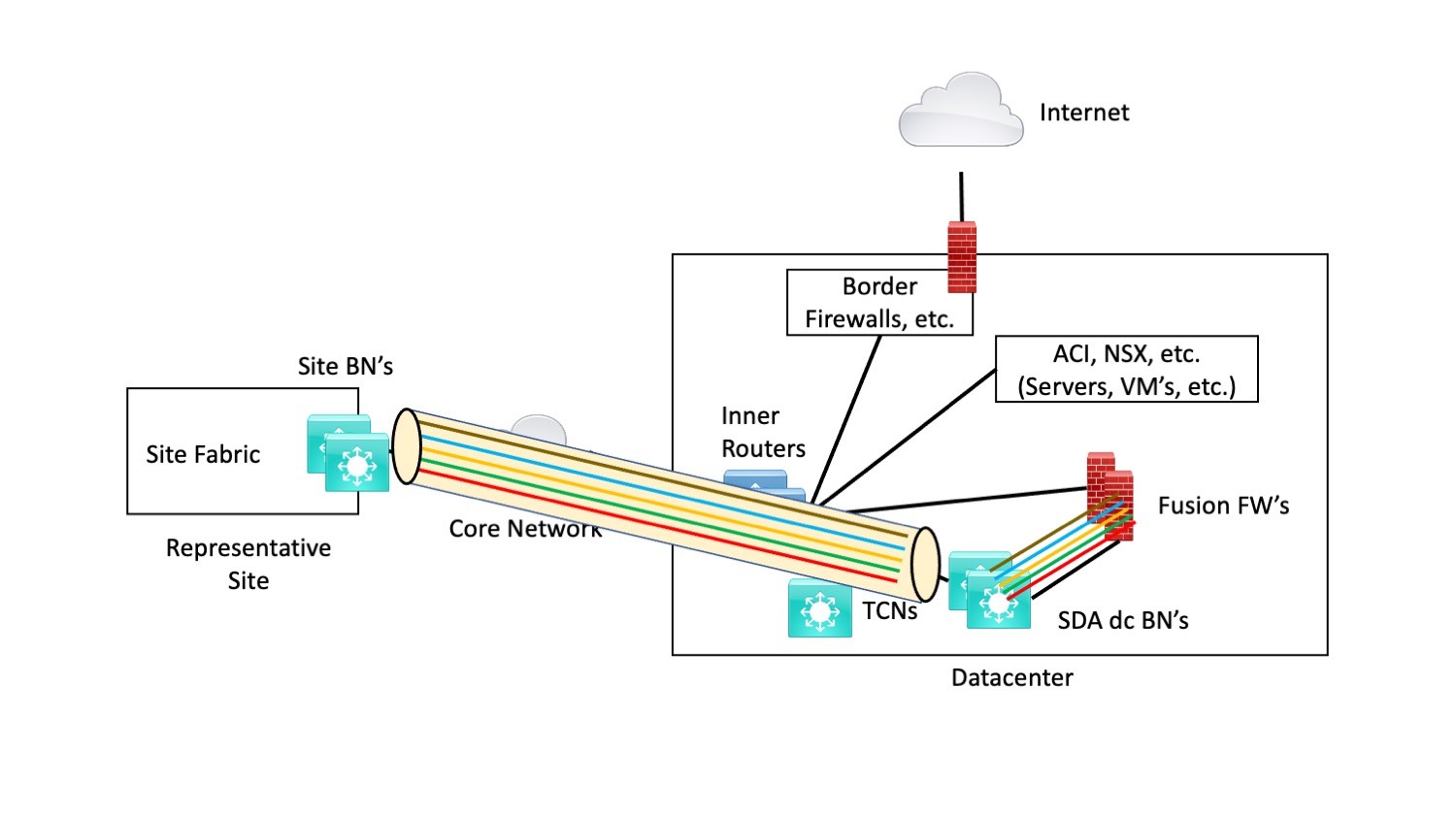
The third approach discussed previously was SD-Access Transit. The following diagram shows how that works. SDA Transit uses automatic VXLAN tunnels between sites or to the datacenter BN’s. Separate logical or physical interfaces maintain the VN / VRF level segmentation into the fusion firewall (FFW). As before, the FFW has pxGrid and SXP available to differentiate security groups and enforce SGACL’s.
Lab
I‘ve had the luxury of working in a lab. Lesson learned: the DNAC GUI is not great at un-doing things.
After having the pleasure of manually cleaning up a DNAC configured switch, I‘ll note that it might be faster to wipe the config and manually get the switch back onto the network. If you use LAN automation, that‘s probably about the quickest way to go. I hear that DNAC does better with configuring / changing configurations on switches that were deployed via LAN automation. I haven‘t tested that.
Right now, there is a strong benefit to getting your process nailed down beforehand. It‘s not a steep learning curve. Getting your mistakes out of the way on a non-production network has value. It also has value when you want to check if something works the way you think it does.
Are you considering SD-Access Transit (see below)? You‘ll probably want to get that working in the lab, with a lab “datacenter“ plus core (1 switch?) and a “remote site.” You should test failover at various points while you‘re at it. That means two BN‘s at the site and two in the data center, connected to your fusion firewall(s).
Are you doing WLAN? You might want to sort out the process around DHCP for fabric WLAN in the lab and make sure you understand how that interacts with ISE.
I‘ll have more to say about labbing SD-Access, including diagrams, in subsequent blogs.
Network Performance
Since we‘re considering multiple sites, it is highly likely ISE and DNAC may be located in datacenters rather than at some or most sites. You‘ll want to plan scalability. But also, you‘ll want to consider latency and how that affects the performance of both ISE and DNAC.
ISE Requirements
See ISE Performance & Scale, or your other favorite ISE scaling and performance guide.
DNAC Requirements
For DNAC, network latency of less than 100 msec round trip time is recommended. Up to 200 msec RTT can work but may reduce performance. More than that is not recommended by Cisco.
The RTT from network devices to DNA Center should be less than 100 msec. Higher latency will slow down various DNAC activities, including Image Updates.
See also the other DNAC scaling information (DNAC Scale Metrics).
Pre-Builds
It is a good idea to get your ISE and DNAC set up for HA, clusters, and scaled prior to deployment. You‘ll also want to make sure you have two staff skilled at each since both will become critical. If they don‘t work or are slow, your users won‘t be productive, and you‘ll have senior management breathing down your neck.
So building skills is part of the preparation, particularly for multi-site SD-Access. Starting with ISE based functionality and transitioning to SDA is one approach that can provide time for skills-building by staff, time in which to gain experience.
All this applies to datacenter buildout if you‘re doing SDA Transit or fusion firewall buildout if doing that. Those components need to be up and stable pretty early in deployment.
Which Interconnection Method?
One thing you probably ought to think about way upfront is how you‘ll interconnect the sites. Among other things, your decision will likely affect what equipment you order.
SD-Access supports three means of interconnecting sites:
- IP Transit (global or per-VRF routing between sites)
- Suitable for general IP routed WAN/core network.
- From the prior blog, note that very large sites may need more BN’s, separating internal border and external border nodes.
- If you’re doing per-VRF between sites, you’ll probably want to get all that built upfront.
- MPLS is one approach.
- VRF’s and plain routing with VRF’s is an alternative.
- Given the work either will take, you’ll probably want to plan and only go through it once. Most of the work will be creating the VRF’s, the sub-interfaces or VLANs, and the addressing for the infrastructure links in each VRF. That can all be done via template (assuming consistent device types / CLI) and perhaps automated.
- If you really want to, with the right equipment, etc., you might be able to also use inline SGT’s between sites. That could take a good bit of work! I’m not sure I see why this would be worth it, given that you can use SXP at enforcement points.
- SD-Access Transit (VXLAN tunnels between sites)
- Higher speed MAN advisable, “campus-like” per the CVD.
- Low latency between sites. The CVD specifies less than 10 msec one-way.
- The intervening MAN must be able to forward jumbo MTUs of typically 9100 bytes without fragmentation.
- (At this point, you should be thinking DWDM, dark fiber, metro Ethernet, etc.).
- You’ll need two standalone Transit Control Nodes, generally one per datacenter if you have two separate datacenters. They should not be in the traffic flow to ensure their CPU capacity is dedicated to fast responses for LISP requests.
- SD-WAN Integration (extend VRF’s to SD-WAN router, it extends them across the WAN)
- Lower speed WAN
- Tolerates higher latency between sites
Site Names and Hierarchy
When I first saw some of the Cisco videos about DNAC, they started with the site hierarchy. I‘ve taught network management in the past, and going into admin, RBAC, or setup stuff at the beginning is a real attention killer. My reaction was this is boring admin stuff; SHOW ME THE GOOD STUFF! As in, something that provides value.
Well, to some extent, that‘s all true. BUT! In another very real sense, working with DNAC does start with the site hierarchy. Regions, buildings, floors.
So, I recommend getting that out of the way and doing it well. This is one thing you really are not going to want to have to redo: most things in DNAC are organized around the site hierarchy. So, get it right the first time!
I used to joke that server people, phone people, and network groups each have site names that are about 80% the same and 20% different from each other‘s names. That may still be true – but I lack fresh data. (This used to come up when correlating site circuit data from phone or WAN people and network device inventories from network people. And thank goodness I haven‘t had to play that game lately.)
So you‘re going to need to get a good set of authoritative site names, ones that everyone will recognize and use.
I‘m big on authoritative names. I like building site names or well-defined abbreviations of them into device names and other things. So that list of site names is an important first step.
Next, you‘ll want to consider how you want to group them. By continent? By country? Are there different regional teams managing sites? Etc.
You‘ll also want to know about the buildings at a site. How many floors? Can you get floor maps for WLAN? Key question: what are their street address(es) so that DNAC can fill in Latitude and Longitude and do mapping for you, where possible.
Which Segments?
Just in case you missed it: do not start with many segments; you‘ll hate yourself!
Start with the minimum tolerable level of segmentation that sets you up with the security groupings you‘ll need going forward.
This is a good time to talk to various teams about the security and regulatory requirements. You‘ll want to find out what the written and the understood policies are around HIPAA and PHI, PCI, and PII. You‘ll also want to find out about other regulated or protected items, e.g., criminal and security info systems that a government public safety group ties into. Be sure to do your due diligence to at least find out what such items might be and what the network currently does to secure them.
Ideally, the organization will have written policies for each such set of regulated or protected items. As the saying goes, “get it in writing.”
Real-world experience is that you may find the organization lacks some such documents, or they are unclear and fail to provide you with actionable requirements.
The challenge here is that identifying and meeting with all the relevant groups can take up a lot of time. Pinning down policies, even longer. With management approval, you may (or may not) want to move your SD-Access project along, on the assumption that SD-Access can accommodate most of the forms of network boundaries short of air gaps, and assuming you will be able to adjust if needed in the future. Otherwise, you may end up waiting a long time for the benefits of SD-Access (assuming that‘s why you‘re trying to do it in the first place).
All this drives your initial set of VN‘s and SG‘s.
Different types of sites, e.g., office versus factory (“OT“), should also be considered. Conceivably, you might have one set of VN‘s and SG‘s for offices, another for factory/warehouse, with some overlap for office/management staff at such sites.
Security Strategy
Another planning item is a security strategy. Where are the various enforcement points?
What devices/rulesets control each of the following:
- User to user, different SG‘s in same VN
- User to user, different SG‘s in different VN‘s
- User to server / VM, for the various SG‘s and VN‘s
- User to Internet flows
- Server to server/app to app / VM to VM in the data center(s)
Enforcement points generally include:
- SDA fabric
- Fusion firewall (or router)
- Server firewall / ACI / NSX
- Edge firewall/complex (IPS, etc.)
IP Pools
Each fabric site is going to need several IP pools, including some that repeat for each VN.
Do you want sites to be a summarizable IP block? Or do you want to have several blocks based on functionality, e.g., VoIP pools out of a bigger overall VoIP pool? Do you want summarization by site, or by function / VN, or what?
Note that summarizability is not a requirement for SDA. I happen to default to site-summarizability, since I think it helps to have some idea where the endpoints of a network flow are located. Some people like being able to look at a prefix and spot that it is VoIP, for instance. My preference is for VoIP to be a uniform sub-block of the site block so as to get site and function by knowing how the site blocks are carved up.
Tied into this, when I do a network assessment, I look for rationality to the addressing. Is there a list of, say, 20-30 blocks that tells me a lot about what‘s where? Or is that list on the wall going to be 1,000 entries because /24‘s were given out in ad hoc fashion? (That‘s why I advocate planning your IP pools.)
Your preferences likely vary.
Note: I am likely to separately blog about this topic in more detail, including the complicating factor of how big the various pools need to be. It’s too much to include here.
Late Addition: In a later blog we’ll see that addressing summarizing by VN / VRF may be useful when you have non-SDA security enforcement points.
IP Multicast?
I tend to assume that servers doing IP multicast will likely be in the data center, so why not put the anycast PIM RP‘s one each in two data centers, in a global routing context. Yes, I‘m assuming the ASM form of multicast.
If you‘re doing SDA Transit, you‘ll have to consider tunneled IP multicast versus using native SSM instead to transport multicast.
You can have RP‘s in fabric sites. I prefer not to, assuming that doing so increases the complexity.
Oh, and be sure to lab it.
Testing IP multicast can be fun, especially with a fusion firewall in the path.
Here‘s a quick sketch of how you might do that fairly simply:
- Do a join interface somewhere other than the RP (global context and/or in another fabric site).
- Send a multicast ping in a VRF from a remote fabric site, to transmit multicast into the network.
- You may well not get replies back if a firewall is in the path (multicast out, unicast back = firewall unhappy with the replies).
- So instead, look at your mroute counters along the path to see if they‘re incrementing, say every 5-10 seconds.
- You can set ping to send say 1 million pings. Timeout 0 makes it a bit of a firehose, which may work or may get dropped for various reasons.
If multicast doesn‘t seem to be working, then you‘ll have to troubleshoot it, which falls well outside the scope for this blog!
References
- Cisco Press book, Software Defined Access
- Cisco Software-Defined Access Design Guide
- SD-Access Compatibility Matrix
- Scaling ISE information (Cisco Community page)
Newly added vCiscoLive slides (as of 9/10/2020):
- Cisco SD-Access – Connecting to the Data Center, Firewall, WAN and More ! – DGTL-BRKCRS-2821
- Cisco SD-Access – Scaling the Fabric to Hundreds of Sites – DGTL-BRKCRS-2825


