
This blog is part of a series covering various SD-Access topics.
Previous blogs in this series:
- What Is SD-Access and Why Do I Care?
- Navigating Around SD-Access
- Managing SD-Access Segmentation
- Securing SD-Access Traffic
- SD-Access Single-Site Design
There are a couple of places in the prior blogs where I recommended lab experience.
This blog addresses the obvious question, “what might a lab look like?” Please bear in mind that there is no single right answer. My hope is that by showing what worked for proof of concept at one site, I’ll either provide you with a lab solution or at least give you some food for thought about a lab.
Note: In general, with ACI, SD-Access, and SD-WAN, having a lab helps you work out issues and unknowns before trying them on your production network. Lately, that extends to API automation as well. Yes, DevNet is another tool for coding and testing API interaction. And Cisco’s VIRL (latest version renamed CML-P) can, to a degree, substitute for physical devices.
Lab Diagram
On the theory that a diagram is worth a thousand words, we’ll start with the diagram and follow with the words.
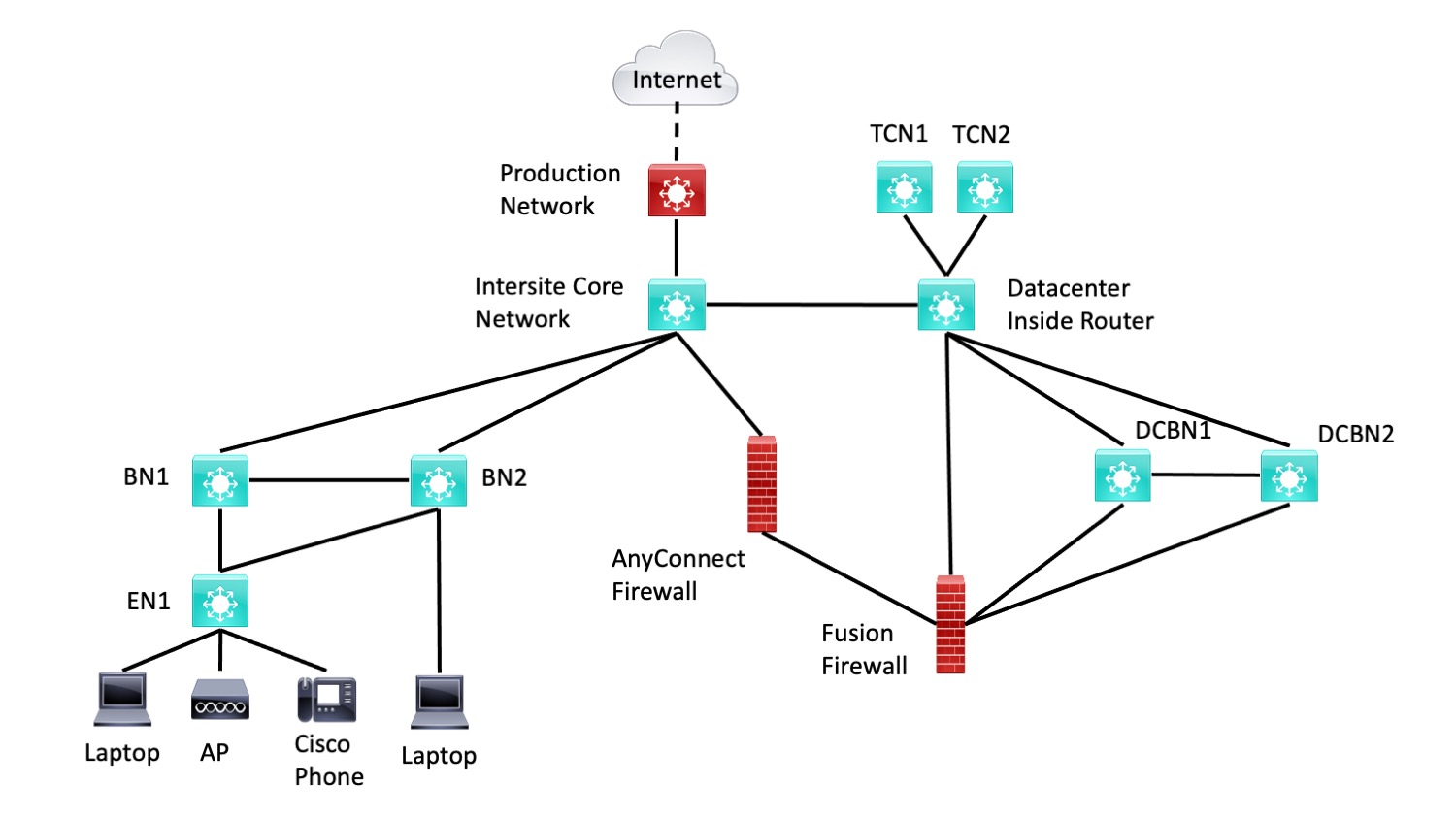
Figure 1: SD-Access Lab Diagram
An explanation of this diagram follows.
Roles
The Core switch connects to the production network, but it also acts as the core MAN / WAN / whatever routed network interconnecting the fabric sites.
The BN1, BN2, EN1 switches act as fabric sites. More details follow below.
The inside router is the router that connects the interior of the data center to the core MAN / WAN / whatever and the other sites. I used retired 3850s for core and inside since they’re not doing anything other than ordinary VLANs and routing, no SD-Access functionality per se.
The dotted line to the Internet indicates that there is a network in between that is not shown.
Connecting to Production
Yes, the lab connects to production. Specifically, it is fairly useful to connect to production somewhere. In these COVID times, it is handy to be able to leverage corporate remote access to do lab work. From that perspective, cabling extra connections and using VLANs in switches as “virtual patch panels” gives us flexibility. We can always remotely shut downlinks that are not needed.
What can work reasonably simple yet provide some lab isolation is static routes.
To set up the lab, you’ll have to assign the lab an IP block anyway. It might as well not conflict with the production network. For what it’s worth, I built the underlay infrastructure above using /27s out of a /24, then used other /24s for the SDA IP pools. So a /21 block of addresses or so might be what you’ll want, assuming you’re willing to use subnets smaller than /24s.
So you can put the lab IP block in a static route on the connected production network router or L3 switch, with next-hop the core switch. And redistribute that into the product IGP. On the core switch, you can point 0/0 at the production network and redistribute it into the lab IGP. I used OSPF for the lab and SDA underlay.
Staying Connected
If you’re working remotely as I was, you really don’t want to lose connectivity.
There are two more things you might want to do that aren’t shown.
First, if a spare console/terminal server is available, you might want to connect it to an Ethernet port on the Core switch and connect the serial connects to the various lab devices.
Second, if that is not available, or you’re a belt and suspenders person, you might connect the management ports of the various devices back to the Core switch in a management VLAN. The theory is that it minimizes the risk of getting disconnected by something you configure. That assumption held up pretty well, but then … Yes, for what it’s worth, I managed to cut myself off anyway doing AnyConnect labwork. I wasn’t aware of a key checkbox in ASDM – we have people who are much more focused on firewalls and security; I’m more a generalist.
So I managed to generate a 10/8 summary that was redistributed. (A behavior I think is a poor default choice.) That route propagated to the core switch and took priority over the 0/0 there, which meant that my assigned remote access IP in network 10 could no longer talk to the lab gear, even the core switch.
As an alternative, you might consider having the management ports on a switch that is directly connected to the production network and not doing any dynamic routing, no VLAN trunking, etc. Or just be mildly careful / have some spare “hands” available. Since the nearest production switch wasn’t anywhere near the lab space, it was a lot simpler to just have one connection to production.
Leveraging the Lab
Note that BN1, BN2, and EN1 let you emulate a smallish fabric site. The attached devices let you work with authentication and authorization and DHCP, and assignment of SGs / SGTs. I didn’t see much point in having a second edge node (EN). You can configure one of the BNs to take on an EN role as well if you want to demonstrate EN to EN tunnels or something else requiring 2 ENs in one site.
If you want to emulate two sites, shut down all but the core connections to BN2, and make it a FIAB site. You can then work with IP Transit between the two sites and the datacenter (on the right) if you want.
Having two BNs in one fabric site lets you test failover, configuration IBGP between the BNs on the crosslink, etc. That same reasoning is why there are two DCBNs (datacenter BNs) in the diagram.
There are two Transit Control Nodes, also for testing failover.
In the lab, the datacenter inside the router is the first L3 switch off the MAN / WAN core. It provides access to ACI, the Internet edge, etc. In the lab, those just happen to be out in the production network. So for lab purposes, the inside router functions as it would in production, but it may seem odd. What’s different is that instead of going deeper into the datacenter to get to most of the data center, edge firewalls, and Internet, well, there is no real data center there. So we route out to production and use the actual product datacenter, edge, etc.
See also the Services section, next.
The virtue of being tied to production and real Internet is that we can do other things, like upgrade code, hit real web IPs, etc. I like to be able to ping 4.2.2.2 and 8.8.8.8, for example, as a test of end to end routing.
In the real world, I had the inside of the AnyConnect firewall connected to DCBN1, figuring that gave more flexibility. We ended up dedicating a VLAN on DCBN1 to simulate cabling the AnyConnect firewall directly to the Fusion Firewall (“FFW”). That is what you might do in production deployment as well.
By the way, not shown: if you want to work with a physical WLC in the lab, you’ll need one. Attach it to the inside switch.
Shrinking This Lab
The core and inside routers / L3 switches could be combined if you’re short on gear.
If you are tight on gear, the FIAB BN2 switch might be repurposed to test failover with two datacenter BNs.
Repurposing the FIAB BN2 switch for a second TCN for failover testing is always an option.
The following diagram uses red ellipses to indicate potential device savings.
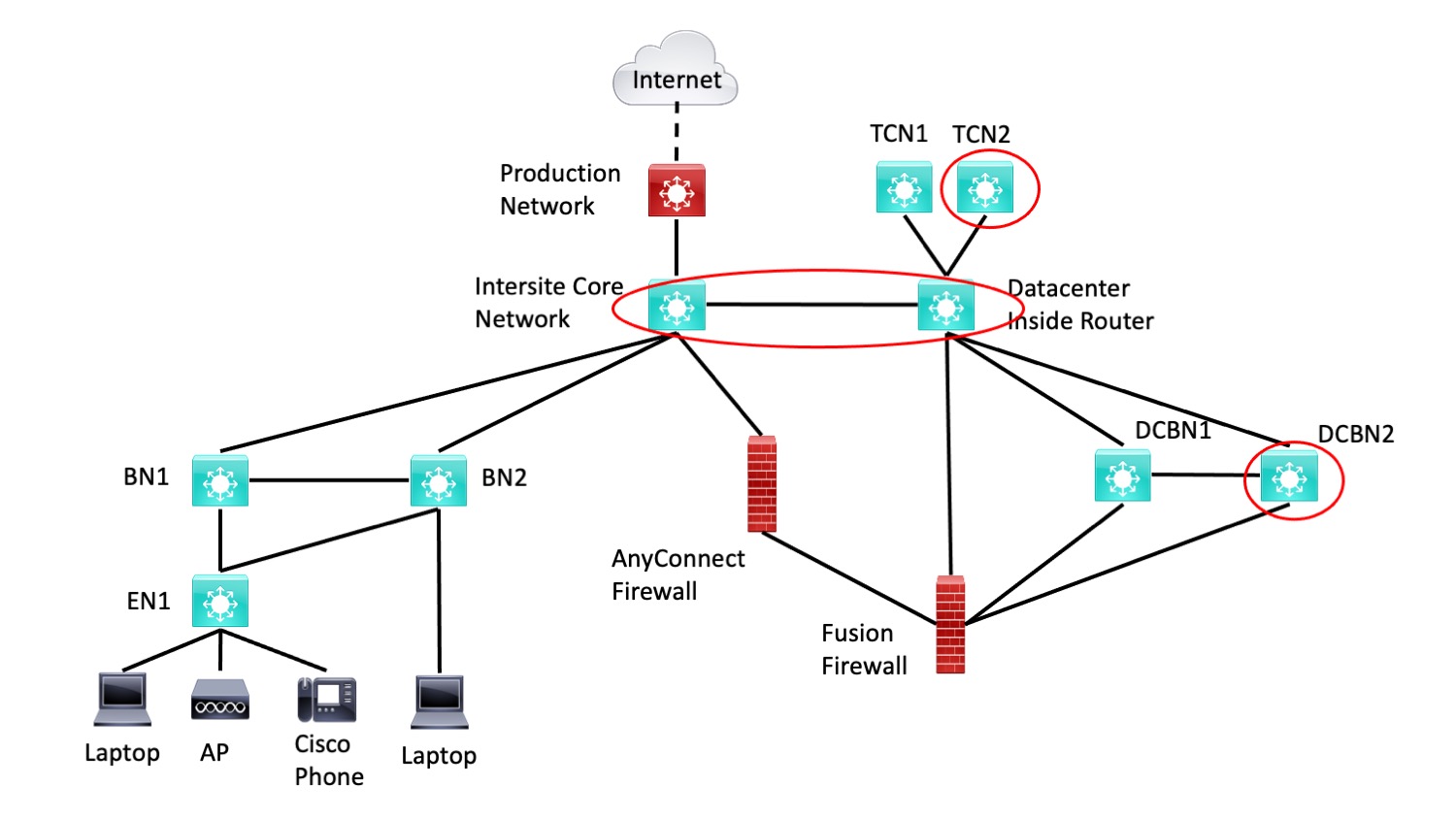
Figure 2: Less Critical Lab Equipment
I’ll note in passing that having the extra gear is useful, so you can leave the SDA lab in place and use it to model changes or migration later on, complete with failover. If you’re tight on gear, then testing failover once and subsequently not testing it is entirely reasonable.
Summing up the repurposed gear discussion above:
- The core and inside switches could be one switch
- The BN2 switch could be used as DCBN2 and TCN2 in testing failover.
That gets the minimum lab down to BN1, BN2, EN1, core/inside the combined router, DCBN1, FFW, and AnyConnect FW (if you’re testing ISE to AnyConnect integration – otherwise, it too can be omitted). Plus small standalone versions of DNAC and ISE located somewhere, and possibly the server hardware to run them on.
Two firewalls are needed since the point of ISE to AnyConnect integration testing would be to confirm that you can enforce SG-based ACLs on the FFW for remote access traffic. That is a topic for another blog. Our lab ran FTD on the FFW but ASA code on the AnyConnect firewall, in part because they both were physically older smaller ASA hardware. In addition, ISE / Security Group integration with ASA-based AnyConnect is a lot more mature than the FTD version, which apparently just recently became supported.
Services
You can probably use your corporate copy of Microsoft Active Directory, etc., for authentication and MS groups. Similarly, you can use the main Call Manager to support the one lab Cisco phone. Both of these uses are very low risk for lab-induced problems.
Since SDA requires that DNA Center be integrated with ISE, you probably will want lab versions of each. That is particularly true if you’re already using DNAC to manage some of the production. If you already use ISE in production, you probably don’t want to take any risks with it.
You might also want a lab FMC VM if you’re running FTD for firewalls. I tested with a CheckPoint FFW and had that working as well, with local Gaia and SmartConsole running on a Windows VM on my Mac.
If you’re going to tie in IPAM, you might want a lab version of that, just to make sure you somehow don’t do something in DNAC that trashes your production IPAM.
With the lab diagram as above, none of these services have to physically be in the lab. They can be running (where possible) as VMs on the company server farm. You will, of course, need admin privileges on those VMs and for the lab DNAC and ISE.
Getting Lab Gear
If you’re pre-staging gear for a deployment, perhaps you can “borrow” equipment to build a lab for 4-8 weeks, while some sites are being deployed in some pre-SDA form, e.g., swapping out old switches but keeping the topology and configurations.
Future? Virtualize It!
Once CML-P (the latest version of VIRL) supports a virtual Catalyst switch image, it might be possible to virtualize all or most of the lab devices and have CML-P communicating with the outside world for the services listed above. I’ve done this with VIRL, e.g., to validate some Python scripting. My contacts tell me that solid Cisco virtual interface code emulating the ASIC chips for Catalyst is a bit lacking, so don’t hold your breath waiting for virtual Catalyst switches.
Wouldn’t that be convenient !!!
Yes, you would need a couple to three powerful servers, with a lot of cores and RAM on the server hosting CML-P.
References


